


然而,AI 领域的科学家们并没有停下前进的脚步。上个周末,人工智能领域最卓越的科学家之一:斯坦福大学终身教授、谷歌云首席科学家李飞飞在未来论坛年会上,为我们做了一场名为“超越 ImageNet 的视觉智能”的精彩演讲。她告诉我们,AI 不仅仅能够精准辨认物体,还能够理解图片内容、甚至能根据一张图片写一小段文章,还能“看懂”视频……
我们都知道,地球上有很多种动物,这其中的绝大多数都有眼睛,这告诉我们视觉是最为重要的一种感觉和认知方式。它对动物的生存和发展至关重要。
所以无论我们在讨论动物智能还是机器智能,视觉是非常重要的基石。世界上所存在的这些系统当中,我们目前了解最深入的是人类的视觉系统。从 5 亿多年前寒武纪大爆发开始,我们的视觉系统就不断地进化发展,这一重要的过程得以让我们理解这个世界。而且视觉系统是我们大脑当中最为复杂的系统,大脑中负责视觉加工的皮层占所有皮层的 50%,这告诉我们,人类的视觉系统非常了不起。
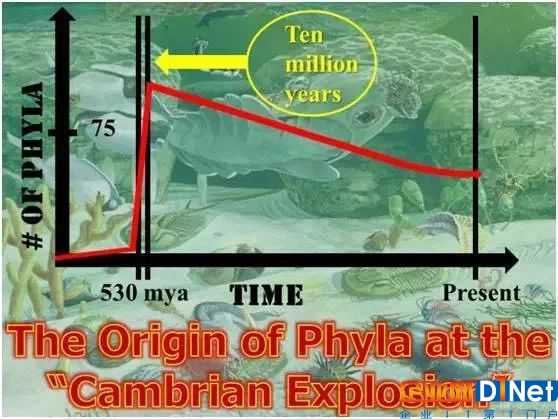
寒武纪物种大爆发
一位认知心理学家做过一个非常著名的实验,这个实验能告诉大家,人类的视觉体系有多么了不起。大家看一下这个视频,你的任务是如果看到一个人的话就举手。每张图呈现的时间是非常短的,也就是 1/10 秒。不仅这样,如果让大家去寻找一个人,你并不知道对方是什么样的人,或者 TA 站在哪里,用什么样的姿势,穿什么样的衣服,然而你仍然能快速准确地识别出这个人。
1996 年的时候,法国著名的心理学家、神经科学家 Simon J. Thorpe 的论文证明出视觉认知能力是人类大脑当中最为了不起的能力,因为它的速度非常快,大概是 150 毫秒。在 150 毫秒之内,我们的大脑能够把非常复杂的含动物和不含动物的图像区别出来。那个时候计算机与人类存在天壤之别,这激励着计算机科学家,他们希望解决的最为基本的问题就是图像识别问题。
在 ImageNet 之外,在单纯的物体识别之外,我们还能做些什么?
过了 20 年到现在,计算机领域内的专家们也针对物体识别发明了几代技术,这个就是众所周知的 ImageNet。我们在图像识别领域内取得了非常大的进步:8 年的时间里,在 ImageNet 挑战赛中,计算机对图像分类的错误率降低了 10 倍。同时,这 8 年当中一项巨大的革命也出现了: 2012 年,卷积神经网络(convolutionary neural network)和 GPU(图形处理器,Graphic Processing Unit)技术的出现,对于计算机视觉和人工智能研究来说是个非常令人激动的进步。作为科学家,我也在思考,在 ImageNet 之外,在单纯的物体识别之外,我们还能做些什么?
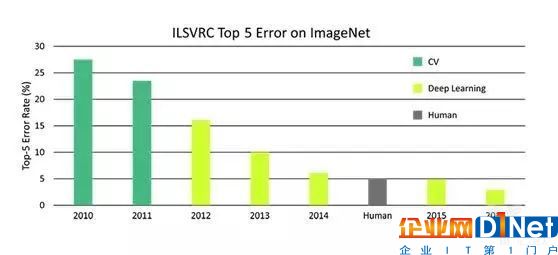
8年时间内计算机对图像分类的错误率统计
8年的时间里,在ImageNet挑战赛中,计算机对图像分类的错误率降低了10倍。
通过一个例子告诉大家:两张图片,都包含一个动物和一个人,如果只是单纯的观察这两张图中出现的事物,这两张图是非常相似的,但是他们呈现出来的故事却是完全不同的。当然你肯定不想出现在右边这张图的场景当中。

两张相似的图片呈现不同的故事
这里体现出了一个非常重要的问题,也就是人类能够做到的、最为重要、最为基础的图像识别功能——理解图像中物体之间的关系。为了模拟人类,在计算机的图像识别任务中,输入的是图像,计算机所输出的信息包括图像中的物体、它们所处的位置以及物体之间的关系。目前我们有一些前期工作,但是绝大多数由计算机所判断的物体之间的关系都是十分有限的。
最近我们开始了一项新的研究,我们使用深度学习算法和视觉语言模型,让计算机去了解图像中不同物体之间的关系。
计算机能够告诉我们不同物体之间的空间关系,能在物体之间进行比较,观察它们是否对称,然后了解他们之间的动作,以及他们之间的介词方位关系。所以这是一个更为丰富的方法,去了解我们的视觉世界,而不仅仅是简单识别一堆物体的名称。

Visual Relationship Detection with Language Priors
更有趣的是,我们甚至可以让计算机实现 Zero short(0 样本学习)对象关系识别。举个例子,用一张某人坐在椅子上、消防栓在旁边的图片训练算法。然后再拿出另一张图片,一个人坐在消防栓上。虽然算法没见过这张图片,但能够表达出这是“一个人坐在消防栓上”。类似的,算法能识别出“一匹马戴着帽子”,虽然训练集里只有“人骑马”以及“人戴着帽子”的图片。
让 AI 读懂图像
在物体识别问题已经很大程度上解决以后,我们的下一个目标是走出物体本身,关注更为广泛的对象之间的关系、语言等等。
ImageNet 为我们带来了很多,但是它从图像中识别出的信息是非常有限的。COCO 软件则能够识别一个场景中的多个物体,并且能够生成一个描述场景的短句子。但是视觉信息数据远不止这些。
经过三年的研究,我们发现了一个可以有更为丰富的方法来描述这些内容,通过不同的标签,描述这些物体,包括他们的性质、属性以及关系,然后通过这样的一个图谱建立起他们之间的联系,我们称之为 Visual Genome dataset(视觉基因组数据集)。这个数据集中包含 10 多万张图片,100 多万种属性和关系标签,还有几百万个描述和问答信息。在我们这样一个数据集中,能够非常精确地让我们超越物体识别,来进行更加精确的对于物体间关系识别的研究。
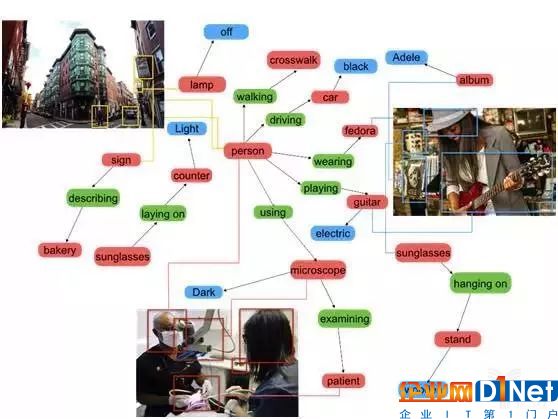
视觉基因组数据集视觉基因组数据集原理示意图
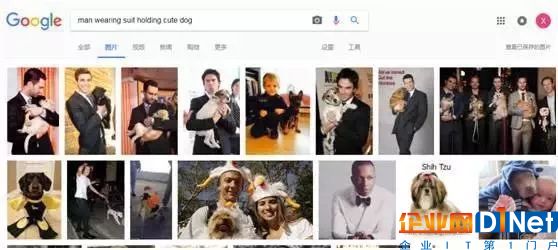
那么我们到底要怎么使用这个工具呢?场景识别就是一个例子:它单独来看是一项简单的任务,比如在谷歌里搜索“穿西装的男人”或者“可爱的小狗”,都能直接得到理想的结果。但是当你搜索“穿西装的男人抱着可爱的小狗”的时候,它的表现就变得糟糕了,这种物体间的关系是一件很难处理的事情。
绝大多数搜索引擎的这种算法,在搜索图像的时候,可能很多还是仅仅使用物体本身的信息,算法只是简单地了解这个图有什么物体,但是这是不够的。比如搜索一个坐在椅子上的男性的图片,如果我们能把物体之外、场景之内的关系全都包含进来,然后再想办法提取精确的关系,这个结果就会更好一些。
2015 年的时候,我们开始去探索这种新的呈现方法,我们可以去输入非常长的描述性的段落,放进 ImageNet 数据集中,然后反过来把它和我们的场景图进行对比,我们通过这种算法能够帮助我们进行很好的搜索,这就远远地超过了我们在之前的这个图像搜索技术当中所看到的结果。
Google搜索准确率示意图
Google图片的准确率已经得到了显著提升
这看起来非常棒,但是大家会有一个问题,在哪里能够找到这些场景图像呢?构建起一个场景图是一件非常复杂并且很困难的事情。目前 Visual Genome 数据集中的场景图都是人工定义的,里面的实体、结构、实体间的关系和到图像的匹配都是我们人工完成的,过程挺痛苦的,我们也不希望以后还要对每一个场景都做这样的工作。
所以我们下一步的工作,就是希望能够出现自动地产生场景图的一个技术。所以我们在今年夏天发表的一篇 CVPR 文章中做了这样一个自动生成场景图的方案:对于一张输入图像,我们首先得到物体识别的备选结果,然后用图推理算法得到实体和实体之间的关系等等;这个过程都是自动完成的。
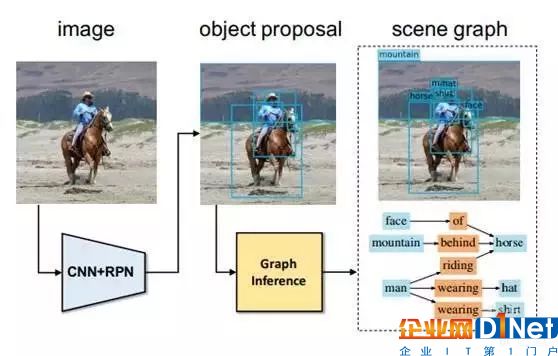
Scene Graph Generation by Iterative Message Passing
人工智能可以像人类一样看懂视频?
Visual Genome 数据集能让计算机更好地了解场景信息,但是还是不够的。而且实际上到现在为止,我们仅仅探索了认知心理学家所讨论的一个概念——现场感知(scene gist perception):只需要轻轻一瞥,就能把握主整个场景中的物体和它们之间的关系。那么在此之外呢?
小编想回过头去看看十年前我在加州理工学院读博士的时候做的一个心理学实验,小编用 10 美元/小时的费用招募人类被试,通过显示器给他们快速呈现出一系列照片,每张照片闪现之后用一个类似墙纸一样的图像盖住它,目的是把他们视网膜暂留的信息清除掉。然后让他们尽可能多地写下自己看到的东西。有些照片只显示了 1/40 秒(27毫秒),有些照片则显示了 0.5 秒的时间,我们的被试能够在这么短的时间里理解场景信息。如果小编给的实验费用更高的话,大家甚至能做的更好。进化给了我们这样的能力,只看到一张图片就可以讲出一个很长的故事。
2015 年开始,我们使用卷积神经网络和递归神经网络算法比如 LSTM 来建立图像和语言之间的关系。从此之后我们就可以让计算机给几乎任何东西配上一个句子。比如这两个例子,“一位穿着橙色马甲的工人正在铺路”和“穿着黑色T恤的男人正在弹吉他”。
不过图像所包含的信息很丰富,一个简短的句子不足以涵盖所有,所以我们下一步的工作就是稠密捕获(dense capture)。让计算机将一张图片分为几个部分,然后分别对各个部分进行描述,而不是仅仅用一个句子描述整个场景。
除了此之外,我们今年所做的工作迈上了一个新的台阶,计算机面对图像不只是简单的说明句子,还要生成文字段落,把它们以具有空间意义的方式连接起来。这与认知心理学家所做的实验当中人类的描述结果是非常接近的。

A Hierarchical Approach for Generating Descriptive Image Paragraphs
COCO 能够根据图片写出几个句子(粉色部分)
新算法能够生成一个段落(蓝色部分)
A Hierarchical Approach for Generating Descriptive Image Paragraphs
但是我们并没有停止在这里,我们开始让计算机识别视频。这是一个崭新且丰富的计算机视觉研究领域。互联网上有很多视频,有各种各样的数据形式,了解这些视频是非常重要的。我们可以用跟上面相似的稠密捕获模型去描述更长的故事片段。把时间的元素加入进去,计算机就能够识别一段视频并对它进行描述。
视觉认知和逻辑推理的结合
最后,小编想谈谈在简单认知以外,我们如何让人工智能达到任务驱动的水平。从一开始人类就希望用语言给机器人下达指定,然后机器人用视觉方法观察世界、理解并完成任务。
在 20 世纪七八十年代的时候,人工智能的先驱们就已经在研究如何让计算机根据他们的指令完成任务了。比如下面这个例子,人类说:“蓝色的角锥体很好。我喜欢不是红色的立方体,但是我也不喜欢任何一个垫着角锥体的东西。那我喜欢那个灰色的盒子吗?” 那么机器或者人工智能就会回答:“不,因为它垫着一个角锥体”。它能够对这个复杂的世界做理解和推理。
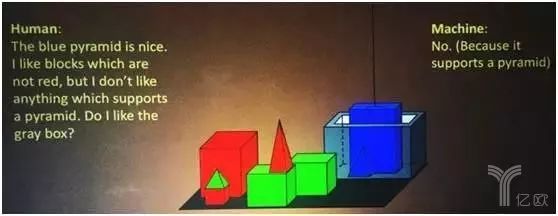
案例示意图一
最近,我们和 Facebook 合作重新研究这类问题,创造了带有各种几何体的场景,我们命名为 Clever dataset。这个数据集包含成对的问题和答案,这其中会涉及到属性的辨别、计数、对比、空间关系等等。我们会给人工智能提问,看它会如何理解、推理、解决这些问题。
我们将人工智能和人类对这类推理问题的回答做了个比较:人类能达到超过 90% 的正确率,机器虽然能做到接近 70% 了,但是仍然有巨大的差距。有这个差距就是因为人类能够组合推理,机器则做不到。
因此我们开始寻找一种能够让人工智能表现得更好的方法:我们把一个问题分解成带有功能的程序段,然后在程序段基础上训练一个能回答问题的执行引擎。这个方案在尝试推理真实世界问题的时候就具有高得多的组合能力。这项工作我们刚刚发表于 ICCV。
比如我们提问“紫色的东西是什么形状的?”,它就会回答“是一个立方体”,并且能够准确定位这个紫色立方体的位置。这表明了它的推理是正确的。它还可以数出东西的数目。这都体现出了算法可以对场景做推理。
人类视觉已经发展了很久,计算机的视觉识别虽然在出现后的 60 年里有了长足的进步,但也仍然只是一门新兴学科。








 京公网安备 11010502049343号
京公网安备 11010502049343号