


那么,算力对企业而言是否可以得到提升?近期在2019第56届设计自动化大会(,创新奇智的CTO张发恩等人联合发布了一篇论文《Efficient GPU NVRAM Persistence with Helper Warps》(https://dac.com/content/2019-dac-accepted-papers)。该论文首次提出一种方法,通过在GPU上使用NVRAM存储的有效并且易于使用的事务处理系统,在特定应用场景下,GPU性能获得了4~5倍的提升。据了解,设计自动化大会简称为DAC,其英文全称ACM/IEEE Design Automation Conference,目前是电子设计自动化和嵌入式系统领域的顶级会议。

上图为:创新奇智CTO张发恩
现状:非易失性存储场景中,GPU性能无法得到完全发挥
张发恩在接受企业网D1Net记者专访时指出:目前算力是人工智能领域各企业都在突破的重点,一般采用GPU与CPU方式,但GPU是CPU算力的50倍,因此算力更加强大。GPU一般用于人工智能模型的训练与人工智能模型的推理两个应用场景下。
当科学家和工程师将GPU应用于人工智能模型训练和推理后,虽然发现带来了巨大的算力提升,但在非易失性存储场景中,GPU性能并没有得到完全发挥,因此,如何进一步提升GPU性能成为众多AI公司的重要关注点。
提升GPU性能 提升算力
算力是人工智能突破的三大要素之一,而提升GPU性能则是提升算力的关键。企业需要及时处理日益增长的海量客户数据。比如零售领域里:智能货柜和渠道陈列平台每天都要为客户处理数百万张高清图片;制造行业里:工业视觉平台需要在车间产线实时处理超清图片;智慧园区:平台需要同时处理多路高清摄像头视频数据;数据智能项目需要及时处理大规模用户行为数据等等。
张发恩发现:当企业的AI训练平台对大量的数据进行处理时,其异构计算对GPU性能的提升提出了更为紧迫的要求。张发恩所在的创新奇智和其他合作伙伴一起,通过大量实验推导,提出了一种方法:通过在GPU上使用NVRAM存储的有效并且易于使用的事务处理系统,可在特定应用场景下,让GPU性能获得了4~5倍的提升。
开放共享 责任担当
当企业网D1Net记者询问张发恩,为何会选择将这一研究成果公布?张发恩说:“人工智能产业需要更多人、更多企业参与进来,形成更大更良好的生态圈,既有基础领域的研究,也有落地的实践应用,这个产业才能走得更远更稳。我所在的创新奇智是一家源于创新工场的人工智能创新科技公司,始终坚信技术为立身之本。公司自成立以来非常重视技术研究,为促进人工智能行业更为快速的发展,我们愿将具备广泛应用价值的技术分享出来,以期让更多企业从中受益,这是一个创新型企业应有的责任担当!”
下附论文解读:

摘要
非易失性随机存取存储器(NVRAM)是近年来出现的一种用于弥补主存和外部存储设备之间性能差距的存储器。为了利用NVRAM的非挥发性,程序应该允许持久化存储,这意味着在断电事件期间必须保持一致性。利用高度的并行性,GPU的设计具有高吞吐量。然而,与DRAM相比,NVRAM具有更低的写入带宽,按照原样使用NVRAM可能会产生次优的总体系统性能。为了解决这个问题,作者提出使用Helper Warp(暂简单译为辅助调度单位)将持久性移出事物执行的关键路径,从而减轻延迟的影响。在带宽限制为1.6GB/s和12GB/s的情况下,该机制分别实现了4.4倍和1.5倍的加速,并且预计即使在NVRAM带宽高达数百GB/s的某些情况下,也将保持速度优势。
介绍
非易失性随机存取存储器(NVRAM)作为一种很有前途的NVRAM替代品,在过去的几年里逐渐成熟起来。MVRAM具有大容量和持久性,因此可以启用和证明诸如事物内存之类的新编程范例。
可字节寻址的持久存储设备(如NVRAM)有几种不同的使用方式。在最简单的形式中,它可以作为DRAM或者缓存的大容量临时替代。这种类型的系统在CPU和GPU上都讨论过,但是没有利用它们的持久性。另一种更复杂的方法是使用NVRAM作为持久数据存储,使其成为事务处理系统(TPS)的一个组成部分。TPS的体系结构通常包括两层:并发协议层,它可能表现为事务内存或者锁定机制,负责检测和解决事务之间的完整性;日志层,以日志的形式执行写操作,以实现持久性,从而在断电事件期间保持数据完整性。在CPU上,这种TPS系统可以涉及硬件、软件和编程语言级别的变化;在GPU上是落后于CPU的,因为在GPU上存在基于事务内存的工作但在当前时刻不存在基于NVRAM的TPS系统。
尽管NVRAM的存储密度较大,但它提供的带宽比DRAM的缓存要少。因此,需要很好地管理带宽引起的延迟,以避免性能下降。为了减轻带宽差距带来的损失,需要采用软硬件结合方法。
本文主要有以下三点贡献:
(1)在这篇工作中作者首次提出了在GPU上使用NVRAM存储的有效并且易于使用的事务处理系统。
(2)作者提出使用Helper Warp,利用GPU的闲置计算资源来缓解写入带宽的限制。
(3)作者建立了一种在不同的程序下能够自适应地启用Helper Warp(辅助调度单位)达到最佳性能的机制。
高效的GPU NVRAM持久性支持
事务处理通常由并发控制和持久性日志记录两部分组成。论文研究的系统采用软件事务内存(STM)进行并发控制。作者提出的STM算法采用了快速冲突检测以及重做日志记录,并解决与全局所有权记录的冲突。写/读集跟踪的粒度是一个32位机器字。对较大数据的访问被视为多个32位机器字。该算法不区分读与写,并通过支持线程ID较低的事务来解决冲突。具体的算法步骤如图2所示。

图2:论文中使用的STM算法
在上述TM算法中,对NVRAM的写入发生在成功提交期间。在默认的严格的Persis-tency模型下,事务必须等待persist操作完成之后才能声明提交成功。这将NVRAM写延迟添加到事务执行的关键路径上,从而增加时间开销。为了解决这个问题,论文作者提出了一个commit过程,它利用Helper Warp将延迟移出关键路径。
带有辅助调度单位的高效日志系统

图3:论文提出框架中的事务时间线
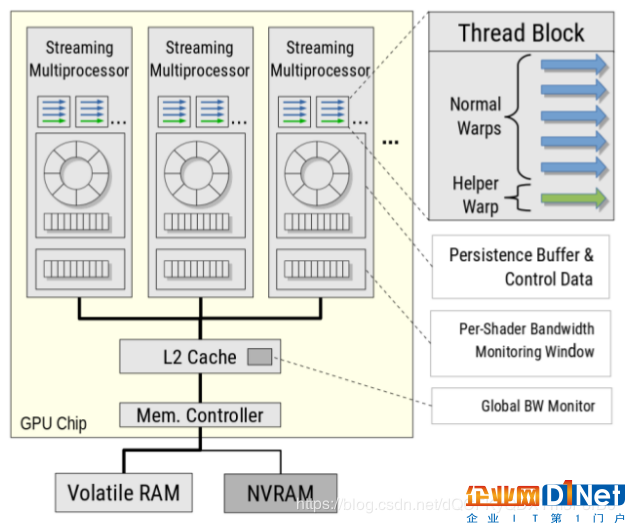
图4:总体系统框架
作者提出的方法使用辅助调度单位来分离事务的提交和持久步骤。辅助调度单位负责处理事务的持久性部分,使持久操作能够与事务的其余部分异步完成。图3显示了添加了辅助调度单位的总体提交协议。
每个线程块中都有一个辅助调度单位,它通过每个线程块共享内存与正常调度单位通信。此外,每个流多处理器(SM)都有一个带宽监控窗口,用于跟踪运行时的瞬时带宽占用情况。图4演示了作者提出的框架,它包括内存拓扑和添加的部分。易失性RAM和非易失性RAM之间的联系类似于最近的AMD Vega框架,该框架旨在支持异构内存框结构,如SSD和DRAM。
系统评估

图6:基准测试的总体运行时间,启用了辅助调度单位(绿色)和禁用了辅助调度单位(红色)
图6展示了使用实验设置的基准测试的运行时间,包括启用和禁用辅助调度单位。这些线表示运行时间随着NVRAM带宽限制而变化的趋势。绿色和红色的线和点分别表示启用和禁用辅助调度单位的运行时间。随着带宽的降低,两种配置的运行时间都会增加。不过,没有辅助调度单位的运行时间最终会增长得更快,并超过启用辅助调度单位的运行时间。这两条运行时间存在交叉点。H1的交叉点高达484GB/s(这意味着即使在易失性RAM带宽下,辅助调度单位的性能也会更好),而BVH1的交叉点则低至11.75GB/s。

图7:基准测试A1的块级事务提交时间线

图8:基于元数据TM的事务平均执行时间的细分
图7展示了基准测试A1中第0块中事务的提交时间线。可以看出,当持久性带宽限制为1.6GB/s时,连续提交会出现很大的差距。由于不同块之间的行为是相似的,这种差异将直接转化为更长的总体运行时间。有了辅助调度单位,差距明显减小,从而大大缩短了基准测试的运行时间。
图8展示了线程块0中事务执行时间的细分情况,其中辅助调度单位静态地打开和关闭。由于带宽有限造成的每个sistence阶段的延迟会导致“caso-cade”效应,使得其他提交事务的时间比带有辅助带调度单位的时间长。这是由于调度单位级别的差异和持有所有权记录使得提交事务需要等待冗长的持久性操作的完成。这也增加了中止率。通过启用辅助调度单位,持久性可以更快地完成,并且“级联”效应得到了缓解。
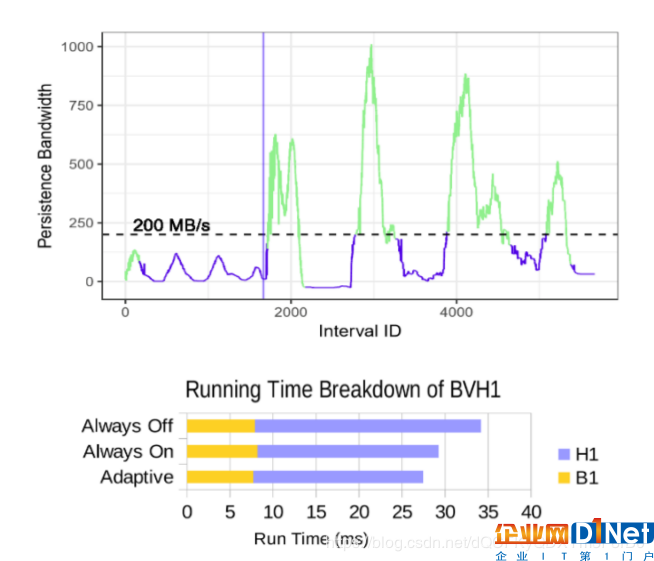
图9:基准测试B1+H1的持续带宽趋势,带有辅助调度单位的自适应切换(上图)和3种配置的运行时间细分(下图)
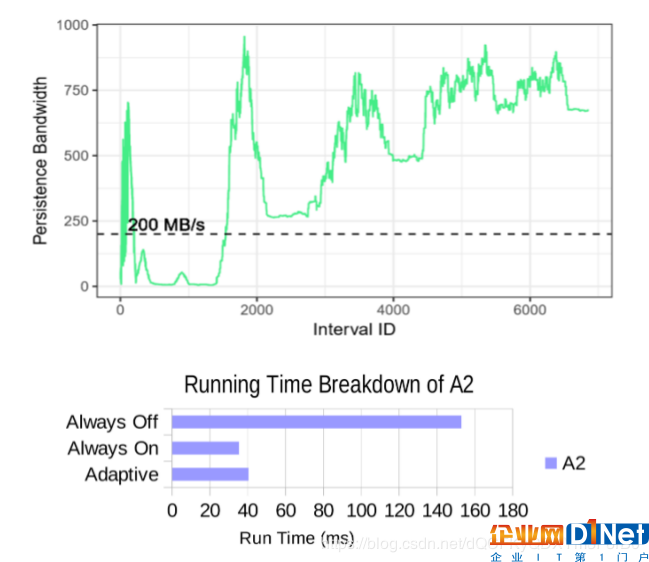
图9显示了辅助调度单位在操作中的切换以响应不断变化的持久性带宽。总的来说,切换显著减少了H1内核的时间,与总是关闭辅助调度单位相比运行时间提高了20%,与总是打开辅助调度单位相比运行时间提高了6%。
图10:基准测试A2的持续带宽趋势,关闭辅助调度单位(顶部)和3种配置的运行时间细分(底部)
与BVH基准测试相反,其他一些基准测试将观察到提交带宽高于大多数程序执行的阈值,比如A2。其持久性带宽趋势可以在图10(顶部)中观察到。对于这个基准测试,始终静态地打开或关闭辅助调度单位会导致轻微的性能损失,如图10(底部),这是由于切换所涉及的开销造成的。
结论
在本文中,作者观察到事务GPU程序的性能下降来源于NVRAM的带宽限制,这种限制导致了长时间的持久性延迟。当NVRAM用作主存的临时替代品时,延迟将直接添加到事务的关键路径上,从而使事务的运行时间更长。此外,这种延迟可能会影响位于相同调度单位的其他线程,从而导致整个基准测试的运行时间更长.
作者提出了Helper warp这个概念,它由位于片上共享内存中的提交缓冲区组成,事务提交将被重定向到该缓冲区。这将从关键路径中移除时间开销,使持续性操作更快。作者还提出了一种方法,使辅助器仅在需要最好性能时才使用。在某些情况下,阈值可能高达每秒数百GB。这包括今天和不久的将来可用的NVRAM带宽范围。








 京公网安备 11010502049343号
京公网安备 11010502049343号