


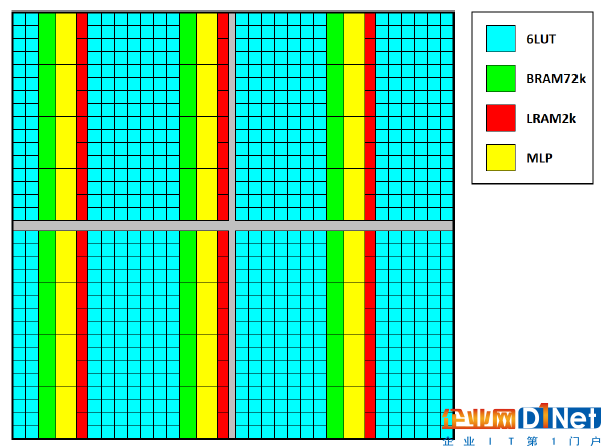
新型纵向连接和MLP级串联路径
其中查找表的所有方面都得到了增强,以支持使用最少的资源来实现各种功能,从而可缩减面积和功耗并提高性能。其中的更改包括将ALU的大小加倍、将每个LUT的寄存器数量加倍、支持7位函数和一些8位函数、以及为移位寄存器提供的专用高速连接。使用LUTS构建附加乘法器,使得有价值的低精度乘法通过最有效的FPGA来实现。
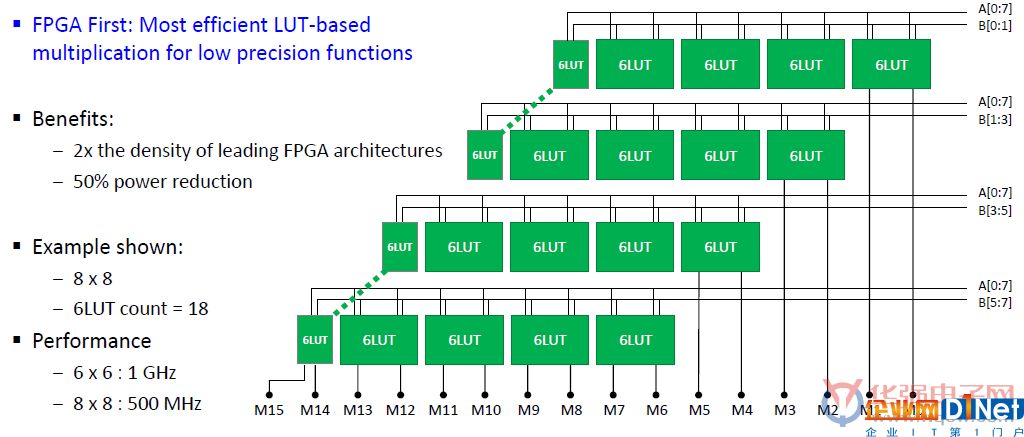
基于GE4LUT的乘法器:比其他FPGA架构更有效
另外,核心架构的研发创新同时能满足多种工具的支持也是非常重要的。Achronix的ACE设计工具中包括了Speedcore Gen4 eFPGAs的预先配置示例实例,它们可支持客户针对性能、资源使用率和编译时间去评估Speedcore Gen4的结果质量;Achronix现已可提供支持Speedcore Gen4的ACE设计工具。Speedcore采用了一种模块化的架构,它可根据客户的要求轻松配置其大小。Achronix使用其Speedcore Builder工具来即刻创建新的Speedcore实例,以便满足客户对其快速评估的要求。
最佳的人工智能/机器学习加速器
正是基于以上新架构的技术,使得Speedcore Gen4对人工智能/机器学习应用的高密度和针对性计算产生了显著增加的需求。与以前的Achronix FPGA产品相比,新的Achronix机器学习处理器(MLP)利用了人工智能/机器学习处理的特定属性,并将这些应用的性能提高了300%。这是通过多种架构性创新来实现的,这些创新可以同时提高每个时钟周期的性能和操作次数。
新的Achronix机器学习处理器(MLP)是一个完整的人工智能/机器学习计算引擎,支持定点和多个浮点数格式和精度。每个机器学习处理器包括一个循环寄存器文件(Cyclical Register File),它用来存储重用的权重或数据。各个机器学习处理器与相邻的机器学习处理器单元模块和更大的存储单元模块紧密耦合,以提供最高的处理性能、每秒最高的操作次数和最低的功率分集。这些机器学习处理器支持各种定点和浮点格式,包括Bfloat16、16位、半精度、24位和单元块浮点。用户可以通过为其应用选择最佳精度来实现精度和性能的均衡。
为了补充机器学习处理器并提高人工智能/机器学习的计算密度,Speedcore Gen4查找表(LUT)可以实现比任何独立FPGA芯片产品高出两倍的乘法器。领先的独立FPGA芯片在21个查找表可以中实现6x6乘法器,而Speedcore Gen4仅需在11个LUT中就可实现相同的功能,并可在1 GHz的速率上工作。
解决带宽爆炸问题 目标市场的现在与未来
那么采用台积电7nm工艺节点的Speedcore Gen4,主要针对新兴人工智能/机器学习和高数据带宽应用的爆炸式需求外,还有哪些目标市场呢?Steve向《华强电子》表示,计算加速度,网络加速,5G基础设施, 智能驾驶这些都是他们的目标市场。这些应用程序具有相同的要求:高性能、低功耗、低延迟、可编程硬件加速器。过去几年,存储和网络主导了FPGA用户群,但未来几年,计算端的需求将远远超过存储和网络,并都将沿着稳定的增长线继续发展,在机器学习,高性能计算,数据分析等领域,FPGA将更有用武之地。Steve尤其看好网络加速和5G市场的应用前景,比如在5G基础设施方面的压缩/减压,非结构化数据匹配 ,数据库加速,适应前沿标准的协议适应性,基带和分裂L1加速,基于人工智能的波束形成,放大器预失真,移动边缘计算这些细分市场都对高性能FPGA有着强烈的需求。
在网络加速方面,固定和无线网络带宽的急剧增加,加上处理能力向边缘等进行重新分配,以及数十亿物联网设备的出现,将给传统网络和计算基础设施带来压力。这种新的处理范式意味着每秒将有数十亿到数万亿次的运算。传统云和企业数据中心计算资源和通信基础设施无法跟上数据速率的指数级增长、快速变化的安全协议、以及许多新的网络和连接要求。传统的多核CPU和SoC无法在没有辅助的情况下独立满足这些要求,因而它们需要硬件加速器,通常是可重新编程的硬件加速器,用来预处理和卸载计算,以便提高系统的整体计算性能。经过优化后的Speedcore Gen4 eFPGA已经可以满足这些应用需求。
另外,对于FGPA成本这个问题,Steve也给出了肯定的答复,采用新架构新工艺的最新Speedcore eFPGA IP,和上一代产品基本持平,不会增加用户成本。对于已量产的Speedcore架构,Achronix可在6周内为客户配置并提供Speedcore eFPGA IP和支持文件。采用台积电7nm工艺节点的Speedcore Gen4将于2019年上半年投入量产,Achronix还将于2019年下半年提供用于台积电16nm和12nm工艺节点的Speedcore Gen4 eFPGA IP。
但Speedcore Gen4已经有市场实例,Micron日前推出GDDR6存储器就是采用Achronix台积电7nm工艺技术的FPGA芯片,实现了高达16 Gb / s的吞吐量。GDDR6针对包括机器学习等诸多要求严苛的应用进行了优化,这些应用需要数万兆比特(multi-terabit)存储宽带,从而使Achronix在提供FPGA方案时,其成本能够比其他使用可比存储解决方案的FPGA低出一半。








 京公网安备 11010502049343号
京公网安备 11010502049343号