


什么是Data Pipeline?
今天我主要跟大家聊聊Data Pipeline在数据工作中的实际应用。在我们的日常工作中,无论是机器学习的建模,还是数据产品开发,Data Pipeline实际上都是一个不可或缺的部分。特别是随着数据来源更加多样化、复杂化以及数据量的飞速增长,搭建一个高效的Data Pipeline,不仅能使你的工作事半功倍,更是很多复杂问题得以解决的关键所在。
我们先来看Data Pipeline的概念。从英文字面上看,Pipeline翻译成中文,其实有两层意思,它可以是管道、也可以是管道运输的意思。通俗点儿来讲,Data Pipeline可以理解为是一个贯穿了整个数据产品或者数据系统的一个管道,而数据就是这个管道所承载的主要对象。Data Pipeline连接了不同的数据处理分析的各个环节,将整个庞杂的系统变得井然有序,便于管理和扩展。从而让使用者能够集中精力从数据中获取所需要的信息,而不是把精力花费在管理日常数据和管理数据库方面。
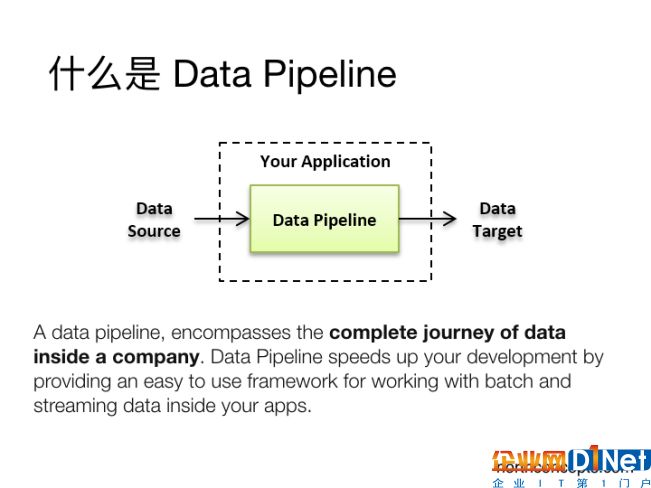
(图片说明:Data Pipeline沟通了数据源和数据应用的目标,包含了一家公司内部的数据流动全过程)
在如今的实际数据工作中,我们需要处理的数据常常是多种多样的。比如说设想这样一个场景:如果我们需要对某一个产品进行一些分析,数据的来源可能是来自于社交媒体的用户评论、点击率,也有可能是从销售渠道获取的交易数据、或者历史数据,或者是从商品网站所抓取的产品信息。面对这么多不同的数据来源,你所要处理的数据可能包含CSV文件、也可能会有JSON文件、Excel等各种形式,可能是图片文字,也可能是存储在数据库的表格,还有可能是来自网站、APP的实时数据。
在这种场景下,我们就迫切需要设计一套Data Pipeline来帮助我们对不同类型的数据进行自动化整合、转换和管理,并在这个基础上帮我们延展出更多的功能,比如可以自动生成报表,自动去进行客户行为预测,甚至做一些更复杂的分析等。
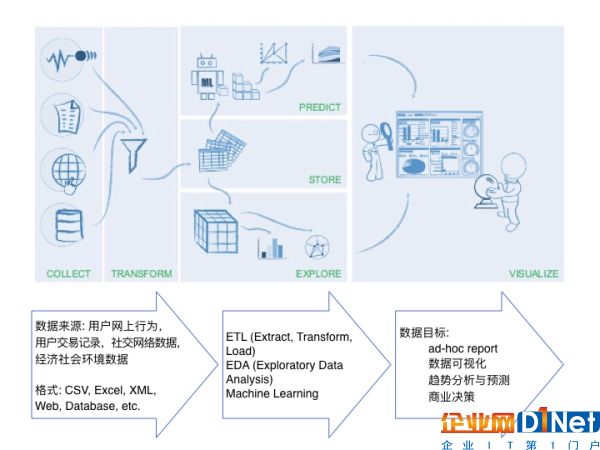
(图片说明:从数据源到数据处理,再到实现数据目标的过程)
对于Data Pipeline,很多人习惯于将它和传统的ETL(Extract-Transform-Load,指的是将数据从来源端经过抽取、转换、加载至目的端的过程)来对比。相对于传统的ETL,Data Pipeline的出现和广泛使用,主要是应对目前复杂的数据来源和应用需求,是跟“大数据”的需求密不可分的。
在实际应用中,目前Data Pipeline在机器学习、任务分析、网络管理、产品研发方面都是被广泛采用的。像是Facebook、Google或是国内的百度、腾讯这样的数据驱动型的科技巨头,它们的任何一个产品的开发,都有一支庞大的数据工程师队伍在后台对整个产品的Data Pipeline进行设计开发和维护。
很多时候,我们甚至可以说,Data Pipeline的成败是整个产品成败的关键。
Data Pipeline在机器学习中的应用案例
Data Pipeline的应用有很多,我主要介绍一下其在机器学习中的应用。尽管在机器学习领域的应用只是Data Pipeline的一个小应用,但却是非常成功的。
对于机器学习来说,Data Pipeline的主要任务就是让机器对已有数据进行分析,从而能使机器对新的数据进行合理地判断。
我想很多人都对Kaggle有所耳闻,可能也有一些人参与过Kaggle的项目。Kaggle是一个数据分析的平台,企业或者研究者可以描述数据方面的问题,把对模型的期望发布到kaggle上面,以竞赛的形式向广大的数据科学爱好者征集更有效的解决方案。

上面这张图,是我从一位经常参与Kaggle项目的达人的博客中拿到的。在和很多Kaggle达人的接触中,其实我们可以发现,他们大多数都会将Data Pipeline整合到自己的机器学习建模的流程中。
这张流程图基本涵盖了绝大多数机器学习要做的事情。如果你有一套合理的Data Pipeline来帮助你自动进行机器学习,那么其实可以省去大量的琐碎的环节,从而把精力集中在具体模型的分析上。
下面我们通过一个简单的机器学习案例来看一下Data Pipeline是怎样用于实际问题的。在这个案例中,我们用到的数据是来源于亚马逊的产品分类信息,其中包含了产品介绍、用户对产品的评分、评论,以及实时的数据。这个项目的主要目的是希望可以用这些实时获取的数据构建模型,从而对新的产品进行打分。

在这个项目中,其实涉及了两个Data Pipeline。第一个Data Pipeline是用于构建基本的模型。如下面这个流程图。就是在机器学习过程中最基本的流程,包括了读取数据、探索分析、模型选择以及评估等。有了Data Pipeline,大大提升了运行效率。
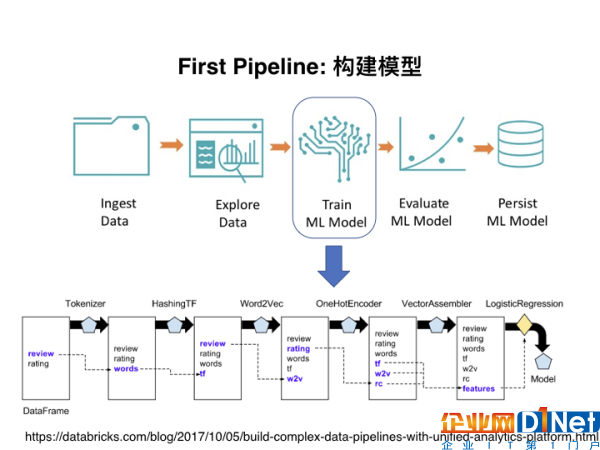
这样一个类似模块化设计的Data Pipeline,其应用到的很多组件在之前的代码中就已经设定好。如果我们在后续需要对Data Pipeline进行修改,只需要去修改最初的某个定义就可以。对于广大码农来说,这可以说是节省了很多重复性的工作,而且使得代码更加简洁,查错也更加方便。
有了最基本的模型,下一步就是构建第二个Data Pipeline,使其服务于实时预测。因为目前,数据是每分每秒都在更新,为了追求预测的准确性和时效性,大多数的公司都会对数据进行实时或是准实时的分析,从而就有了Data Pipeline的需求。
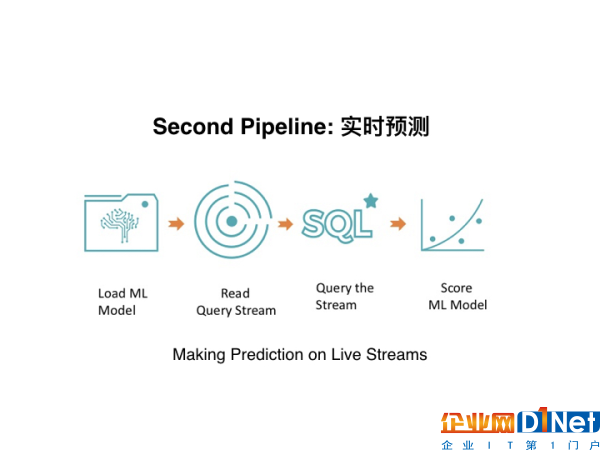
在第二个Data Pipeline中,最重要的两个环节就是上图中的read query stream(读取实时数据)、query the stream(实时计算数据)这两个环节,它主要起到了实时去读取数据、然后再对数据进行实时计算,给用户一个实时的反馈的作用。这样的话,数据就可以实现更大的价值。
第二个案例,则是一个更加具体的案例。很多朋友喜欢从Netflix上看美剧。作为一家成立于1997年,最初以出租DVD为主营业务,现在发展成为美国首屈一指的互联网流媒体服务商,Netflix目前很大一部分业务其实都是基于数据处理和分析来完成的。

如果你通过APP或者是手机去使用Netflix服务,你很可能会遇到下面这样的界面:
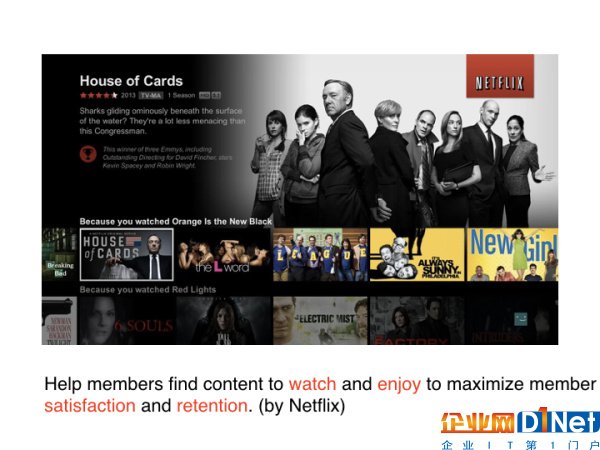
Netflix会根据你的浏览记录来推断你的喜好,从而给你进行个性化的推荐。凭借着这种实时而准确的用户数据来推荐影片,Netflix吸引着更多的用户去成为它的订阅者。而事实上,它这种以数据为核心的商业模式,和它的规模也有很大关系。根据最新的统计结果,Netflix的用户遍及了全球190个国家,每个月用户的总活跃时间达到了30亿个小时
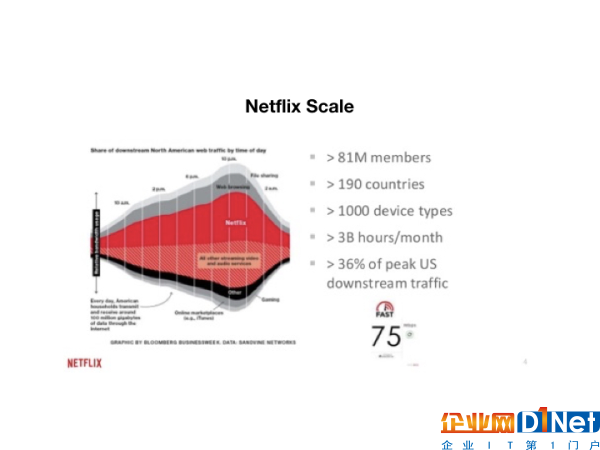
(图片说明:Netflix的用户规模和数据规模等)
有了这么丰富的数据,是非常适合使用Data Pipeline的。Data Pipeline在Netflix的推荐系统中起到的作用是将来自全球的用户数据进行整合分类,导入不同的时间、不同类型的模型中,从而对用户的行为进行一个实时的预测。
Netflix的Data Pipeline系统可以分成三个部分:实时计算、准实时计算、离线部分。
实时计算部分,主要是用于对实时事件的响应和与用户的互动,它必须在极短的时间里对用户的请求作出响应,因此它比较适用于小量数据的简单运算。而至于离线计算,它则不会受到这些因素的干扰,比较适用于大量数据的批处理运算。
准实时运算,则是介于实时和离线之间。它可以处理实时运算,但是又不要求很快给出结果。比如当用户看过某部电影之后再给出推荐,就是准实时运算,可以用来对推荐系统进行更新,从而避免对用户的重复推荐。
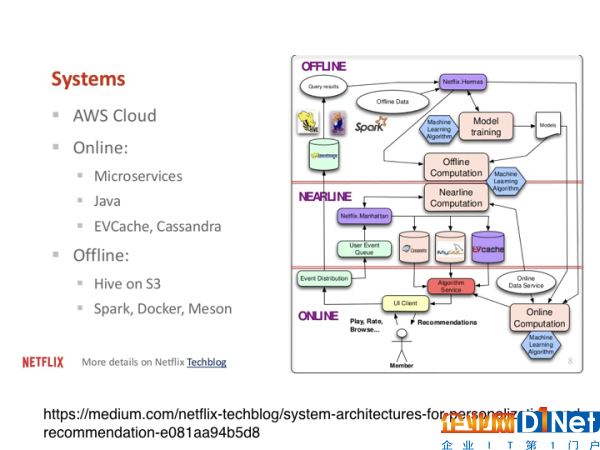
当然,Netflix要搭建Data Pipeline这样的系统,也有一定的技术和硬件要求。
比如,在下图中你可以看到左边列出了很多硬件上的要求。很多是在云端的服务,比如亚马逊云服务(AWS)。在在线的运算系统中,如果对速度的要求很快,可能会用到Cassandra、EVCache。而对于离线的推荐和运算来说,我们需要的是对大数据的存储,而不会太在乎它的速度快慢,所以这时候HIVE ON S3会是一个比较好的选择。
搭建Data Pipeline的常见工具有哪些?
搭建Data Pipeline是一个复杂的数据工程,它牵扯很多因素,比如软硬件协调,资金方面的投入等。这里我不再详细说明。
下面,我想介绍一些常用的Data Pipeline相关工具。
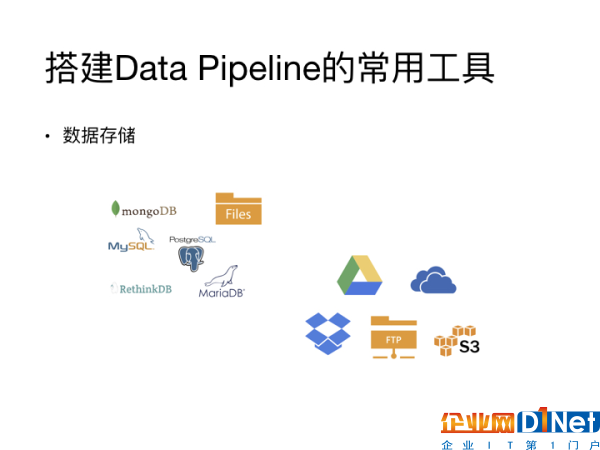
首先是存储方面,这个也是大家最容易接触到的。首先,你需要知道你的数据从哪里来,它的速度、它的数据量是多少。然后你要知道当你的数据经过数据处理之后,Data Pipeline需要把数据以什么样的格式、存储在怎样一个数据环境里。
根据数据格式和数据数量的不同,你需要根据你的目的选择合适的数据存储方式。如果你的数据量特别大,你很有可能需要使用像是Hive这样的基于大数据的数据存储工具。
其次,你需要考虑到你要对数据进行怎样的处理。比如,如果你需要做批量处理、实时分析等,这些问题都可能需要你使用能处理大量数据的工具。像是Spark就是比较流行的的处理方案,因为它包含了很多接口,基本上可以处理Data Pipeline中所需要面临的绝大多数问题。
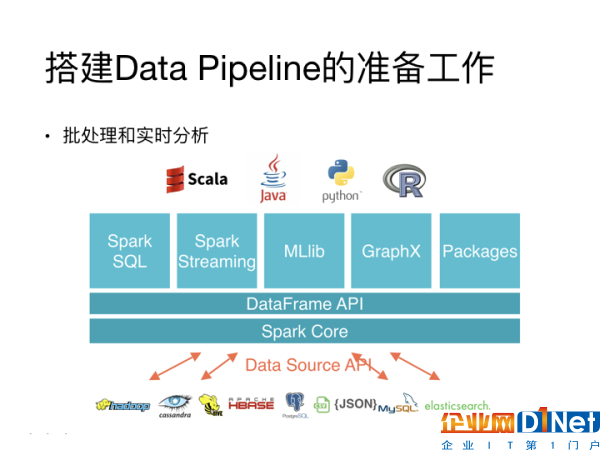
Data Pipeline相关的复杂工具有很多,你需要去认真选择最适合的工具。
这里我想分享一个搭建Data Pipeline可能会用到的小管理工具。它是由Airbnb开发的一款叫做Airflow的小软件。这个软件是用Data Pipeline来写的,对于Python的脚本有良好的支持。它的主要作用是对数据工作的调度提供可靠的流程,而且它还自带UI,方便使用者监督程序进程,进行实时的管理。

在Airflow这个软件中,最重要的一个概念叫做DAG(有向无环图)。关于DAG,前面提到的机器学习案例中其实已经有了应用。在Airflow中,你可以将DAG看成是一个小的流程,这个小流程是由一个个有向的子任务组成,按照事先规定好的顺序来一次顺序执行,最终达到Data Pipeline所要实现的目的。
由于时间关系,这里不再具体展开。简而言之,我想说的是,在数据处理的过程中,Data Pipeline是一个很重要的系统,而在搭建这样的系统中,可以适当通过一些软件来管理,从而获得最好的效果。








 京公网安备 11010502049343号
京公网安备 11010502049343号