


在当今快节奏的分析开发环境中,数据科学家的任务将不仅仅是构建机器学习模型并将其部署到生产环境当中。现在,他们需要负责定期监控、微调、更新、再训练、替换和启动模型-在某些情况下,还需要整合数百甚至数千个模型。
因此便出现了不同层次的模型管理需求。在下面的文章中,我将着重介绍从单一的模型管理到建立整个模型工厂的每一种方法。
机器学习的工作流程基础
您可能想知道,我是如何使用我的训练过程的结果来获得新的数据的?有很多选项,例如在用于训练和以标准化格式导出模型的同一系统中进行评分。或者,您也可以将模型推送到其他系统中,例如将模型作为数据库中的SQL语句来进行评分,或者将模型打包,以便在完全不同的运行时环境中进行处理。从模型管理的角度来看,您只需要能够支持所有必需的选项。
标准流程如下所示:

注意:在现实中,除非有少部分数据处理(转换/集成)是生产中“模型”的一部分,否则模型本身通常都不是非常有用。这就是许多部署选项的不足之处,因为它们仅支持预测模型的部署。
机器学习模型的评估与监控
模型管理的一个重要部分是确保模型保持其应有的性能。正如许多数据科学家所被迫的那样,定期收集过去的数据只能确保模型没有突然改变。持续监控允许您测量模型是否开始“漂移”,即是否由于现实的变化而变得过时。有时,最好使用包括人工标注的数据来测试边界案例,或者只是确保模型不会犯严重错误。
最后,模型评估的结果应该是对模型质量的某种形式的评分,例如分类的准确性。有时,您需要更多依赖于应用程序的度量,例如预测成本或风险度量。然而,对于您如何处理这些评分,则又是另一回事了。
更新和再训练机器学习模型
在下一个阶段,我们将从监视转移到实际管理上来。假设您的监控解决方案开始报告越来越多的错误。在这种情况下,您可以触发自动模型更新、再训练,甚至是完全替换模型。
一些模型管理设置只是训练一个新模型,然后部署它。然而,由于训练可能占用大量的资源和时间,一种更明智的方法是让这种转换与性能相关联。定义一个性能阈值以确保替换现有模型的实际价值。你需要对前一个模型(通常称为冠军模型)和新训练模型(挑战模型)进行评估;对它们进行评分并决定是应该部署新模型还是保留旧模型。在某些情况下,您可能只想在新模型的性能显著优于旧模型时才愿意经历模型部署的麻烦。
即使有了持续的监控、再训练和替换,如果您不在管理系统的其他地方采取预防措施,机器学习模型的模型仍然会有季节性的变化。例如,如果该模型是用来预测服装的销售配额的,那么季节可能将显著的影响这些预测。如果你每个月都进行监控和再训练,年复一年,您自然可以有效地训练模型以适应当前季节。您还可以手动设置季节性模型的组合,这些模型的权重会根据季节的不同而不同。
有时模型需要保证特定情况下的特定行为。将专家知识注入模型学习是实现这一目标的一种方法,但是具有可以覆盖训练模型输出的单独规则模型则是一种更透明的解决方案。
虽然有些模型可以更新,但算法可能会很健忘。很久以前的数据在决定模型参数方面的作用将越来越小。这有时是可取的,但如何适当的调整遗忘速度的确是一个难题。
另一种方法是重新训练模型,从头构建一个新模型。这允许您使用适当的数据抽样(和评分)策略,以确保新模型是在过去和最近数据的正确组合上训练的。
现在,管理过程看起来更像是这样:

管理多个机器学习模型
假设您现在想要持续地监视和更新/再训练整个模型集。您可以使用与单模型情况相同的方式处理此问题,但是对于多个模型,就会出现与接口和实际管理相关的问题。您如何向用户传达许多模型的状态,并让用户与它们交互,以及由谁来控制所有这些流程的执行?必须有一个所有模型的仪表板视图,该视图具有管理和控制单个模型的功能。
大多数工作流工具允许将它们的内部作为服务公开,因此您可以设置一个单独的程序,以确保您的单个模型管理过程被正确地调用。您可以构建单独的应用程序,也可以使用现有的开源软件来编排建模工作流、监督这些流程并总结它们的输出。
当您将大量机器学习模型分组到不同的模型族中时,管理它们也将变得更加有趣。你可以用类似的方法来处理预测相似行为的模型。如果您经常需要新模型,这将特别有用。当模型相似时,您可以通过从集合中的现有模型初始化一个新模型来节省时间和精力,而不是从头开始,或者仅仅根据孤立的过去数据来对新模型进行训练。您可以使用最相似的模型(由对象的相似性度量决定)或混合模型来进行初始化。
模型管理的设置现在看起来是这样的:
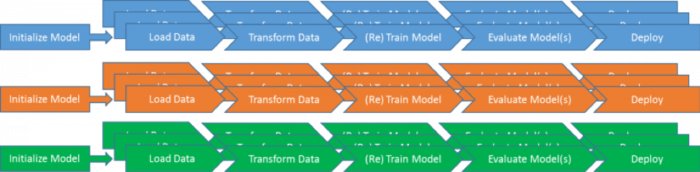
如果您充分抽象了模型之间的接口,您应该能够随意的进行混合和匹配。这将允许新模型重用负载、转换、(重新)训练、评估和部署策略,并以任意方式组合它们。对于每个特定模型,您只需要定义在这个通用模型管理管道中的每个阶段使用哪些特定的流程步骤。
如下所示:
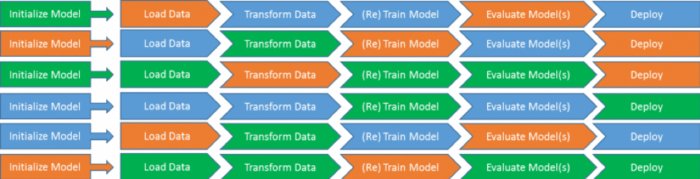
部署模型可能只有两种不同的方式,但是访问数据则有十多种不同的方法。如果你还必须将它分成不同的模型流程族,那么你最终会得到一百多种不同的结果。
机器学习模型工厂
机器学习模型管理的最后一步是创建模型工厂。例如,这可以通过仅定义上面的各个部分(流程步骤)并以配置文件中定义的灵活方式来进行组合配置。然后,无论何时,当有人想要在以后更改数据访问或首选的模型部署时,您只需要调整特定的流程步骤,而不必去修改使用它的所有流程。这是一个极有效的省时方法。
在这个阶段,将评估步骤分为两部分是有意义的,一部分计算模型的分数,另一部分决定如何处理该分数。后者可以包括处理冠军/挑战者场景的不同策略,并且独立于实际得分的计算。
这样,让一个模型工厂投入实际工作将会非常简单。你只需要配置每个流程步骤的哪个具体方案用于哪个模型管道。对于每个模型,您可以自动比较过去和当前的性能,并据此决定是否触发再训练和更新。在关于企业可伸缩模型流程的白皮书中对此进行了详细描述。
虽然其中包含了大量的信息,但是数据科学家将会掌握上述的每一个级别,因为他们也必须掌握。而今天的海量信息将很快变得微不足道。现在,我们必须开发可靠的管理实践,以处理日益庞大的数据量和随之而来的大量模型,以便最终理解这些数据。
Michael Berthold博士是KNIME的创始人兼首席执行官。他在数据分析、机器学习、人工智能和规则归纳方面有超过25年的研究和行业经验。作为康斯坦茨大学、卡内基梅隆大学和加州大学伯克利分校的教授,以及英特尔、Utopy和Tripos的工业专家,Michael有着悠久的学术生涯。








 京公网安备 11010502049343号
京公网安备 11010502049343号