


在这里,你的全身上下都被数据围绕,无处不在的物联网、穿梭自如的无人驾驶汽车让数据源源不断产生,就像开着的水管,数据源一直流出。你发现曾经用于分析大数据的方法已经失效,因为他们更适合批处理。

面对新的数据场景,你迫切需要一种能够同时满足低延时、仅处理一次、顺序保证、检查点的新的存储系统,否则将无法立足于5G时代。
争分夺秒,在你的悉心研发之下,新的存储类型终于诞生了,你将它命名为“Pravega”,取梵语中“Good Speed”之意。

在前两期的内容里,我们介绍了未来大数据环境下需要新的存储类型,即原生的流存储,而Pravega正是为目的这一而生。并介绍了Pravega的关键特性,以及它能给开发人员和公司带来的优势。今天这篇文章,我们将从Pravega的动态伸缩性来谈,并用一份纽约出租车数据写入Pravega,来看它的动态伸缩表现。
作者简介

滕昱
滕昱:就职于Dell EMC中国研发集团,非结构化数据存储部门团队并担任软件开发总监。2007年加入Dell EMC以后一直专注于分布式存储领域。参加并领导了中国研发团队参与两代Dell EMC对象存储产品的研发工作并取得商业上成功。从2017年开始,兼任Streaming存储和实时计算系统的设计开发与领导工作。

黄一帆
黄一帆:毕业于上海交通大学计算机专业,现就职于DellEMC,10 年分布式计算、搜索以及架构设计经验,现从事流式系统相关的设计与开发工作。

周煜敏
周煜敏:复旦大学计算机专业研究生,从本科起就参与Dell EMC分布式对象存储的实习工作。现参与Flink相关领域研发工作。
Pravega属于戴尔科技集团IoT战略下的一个子项目。该项目是从0开始构建,用于存储和分析来自各种物联网终端的大量数据,旨在实现实时决策。其结合了戴尔易安信PowerEdge服务器,并无缝集成到非结构化数据产品组合Isilon和Elastic Cloud Storage(ECS)中,同时拥抱Flink生态,以此为用户提供IoT所需的关键平台。

Pravega能够应对瞬时的数据洪峰,做到“削峰填谷”,让系统自动地伴随数据到达速率的变化而伸缩,既能够在数据峰值时进行扩容提升瞬时处理能力,又能在数据谷值时进行缩容节省运行成本,而读写客户端无需额外进行调整。这一特性对于企业尤其重要,Devops开销在企业中都会被归入产品TCO(Total Cost of Ownership) , 所以产品自身的动态自适应能力将会是必备条件。
下面我们就详细讲述Pravega动态弹性伸缩特性的实现和应用实例。
动态+伸缩性
对于分布式消息系统来说,一个设计良好的,可扩展的分区机制必不可少。分区机制使得读写的并行化成为可能,而一个良好的分区扩展机制使得企业在面临业务增长时可以变得更得心应手。和许多基于静态分区,或者需要手动扩展分区(如Kafka)系统不同的是,Pravega可以根据数据负载动态地伸缩Stream,以此来实时地应对流量负载变化。
Pravega,把繁琐变轻松
在当前大数据技术环境下,我们通过将数据拆分成多个分区并独立处理来获得并行性。例如,Hadoop通过HDFS和map-reduce实现了批处理并行化。对于流式工作负载,我们今天要使用多消息队列或Kafka分区来实现并行化。
这两个选项都有同样的问题:分区机制会同时影响读客户端和写客户端。面对持续数据处理的读/写,我们的扩展要求往往会有不同,而一个同时影响读写的分区机制会增加系统的复杂性。此外,虽然你可以通过添加队列或分区来进行扩展,但这需要分别对读、写客户端和存储进行手动调整,然后需要手动协调调整后的参数。这样的操作不仅复杂,也不是动态的,需要人工介入。

而使用Pravega,我们可以轻松、弹性并且独立地扩展数据的摄入、存储和处理,即协调数据管道中每个组件的扩展。
Pravega Stream的动态伸缩智慧
Pravega对动态伸缩的支持源自于把Stream划分成Segment的想法。
在之前的文章中有介绍过,一个Stream可以具有一个或多个Segment。我们可以把一个 Segment类比成一个分区,写入Stream的任何数据都会根据指定路由键,通过哈希计算路由至某一个Segment。实际应用场景下,我们建议应用开发者基于一些有应用意义的字段,比如customer-id,timestamp,machine-id等来生成路由键,这样就可以确保将同类的应用数据路由至同一个Segment。
Segment是Stream中最基本的并行单元。
• 并行写:一个具有更多个Segment的Stream可以支持更大的写入并行度,多个写客户端可以并行地对多个 Segment 进行写入,而这些Segment可能在物理上分布于集群中的多台服务器上。
• 并行读:对读客户端来说,Segment的数量意味着最大的读并行度。一个具有N个读客户端的读者组可以以最大为N的并行读来消费同一个Stream。这样,当一个Stream中的Segment数量被动态增加时,我们可以相应地增加同等数量的读客户端(同一读者组)来增加并行度;反之亦然,当Segment数量动态减少时,我们也可以减少相应的读客户端来节省资源。
深入剖析
Pravega根据一致性散列算法将路由键散列至“键空间”,该键空间被划分为多个分区,分区数量和Segment数量相一致,同时保证每一个Segment保存着一组路由键落入同一区间的事件。
根据路由键,我们将一个Stream拆分成了若干个Segment,每一个Segment保存着一组路由键落入同一区间的事件,并且拥有着相同的SLO。
同时,Segment可以被封闭(seal),一个被封闭的Segment将禁止写入。这一概念在动态伸缩中将发挥重要作用。
实例说明伸缩过程
假设某制造企业有400个传感器,分别编号为0~399,我们将编号做为routing key,并将其散列分布到 (0, 1) 的键空间中(Pravega也支持将非数值型的路由键散列到键空间中)。随着部分传感器传输频率的变化,我们来观察其Segment的变化。
如图1 所示,在 0~1区间的键空间中,Segment的合并和拆分导致了路由键随着时间的推移而被路由至不同的Segment。
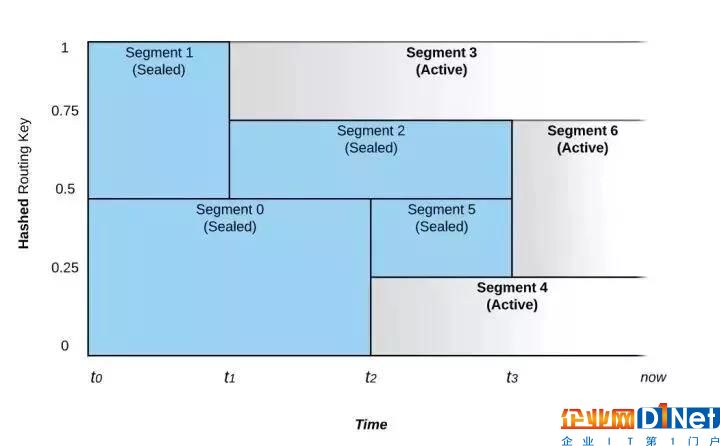
图 1: Segment的合并和拆分对事件路由的影响
上图所示的Stream从时间 t0 开始,它被配置成具有动态伸缩功能。如果写入流的数据速率不变,则段的数量不会改变。
在时间点t1,Pravega监控器注意到数据速率的增加,并且选择将Segment 1拆分成Segment 2和 Segment 3两部分,这个过程我们称之为Scale-up事件。在t1之前,路由键散列到键空间上半部的(值为 200~399)的事件将被放置在 Segment 1中,而路由键散列到键空间下半部的(值为 0~199)的事件则被放置在 Segment 0 中。在 t1 之后Segment 1被拆分成Segment 2 和 Segment 3,Segment 1则被封闭,即不再接受写入。此时,具有路由键300及以上的事件被写入 Segment 3,而路由键在200和299之间的事件将被写入Segment 2。Segment 0则仍然保持接受与t1之前相同范围的事件。
在t2时间点,我们看到另一个Scale-up事件。这次事件将Segment 0拆分成Segment 4和Segment 5。Segment 0因此被封闭而不再接受写入。
具有相邻路由键散列空间的Segment也可以被合并,比如在t3时间点,Segment 2和 Segment 5被合并成为Segment 6,Segment 2和Segment 5都会被封闭,而t3之后,之前写入Segment 2和Segment 5的事件,也就是路由键在100和299之间的事件将被写入新的Segment 6中。合并事件的发生表明Stream上的负载正在减少。
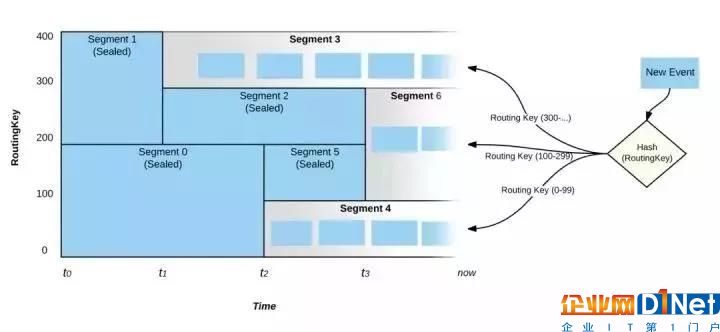
图2: 事件的路由
如图2,在“现在”这个时刻,只有Segment3,6 和4处于活动状态,并且所有活跃的Segment将会覆盖整个键空间。在上述的规则2和3中,即使输入负载达到了定义的阈值,Pravega也不会立即触发scale-up/down的事件,而是需要负载在一段足够长的时间内超越策略阈值,这也避免了过于频繁的伸缩策略影响读写性能。
真真实数据用例
我们使用由美国纽约市政府授权开源的出租车数据,包括上下车时间,地点,行程距离,逐项票价,付款类型、乘客数量等字段。我们把历史数据集模拟成了流式数据实时地写入Pravega。所取的数据集涵盖的是2015年3月的黄色出租车行程数据,其数据量为1.9GB,包括近千万条记录,每条记录17个字段。我们选取了其中12个小时的数据,形成如图3所示数据统计:
黄色和绿色的出租车行程记录包括捕获乘客上车和下车日期/时间,接送和下车地点,行程距离,逐项票价,费率类型,付款类型和司机报告的乘客数量的字段。我们把历史数据集模拟成了流式数据实时地写入Pravega。所取的数据集涵盖的是2015年3月的黄色出租车的行程数据,其数据量为1.9GB,包括近千万条记录,每条记录17个字段。我们选取了其中12 个小时的数据,形成如图3所示数据统计:
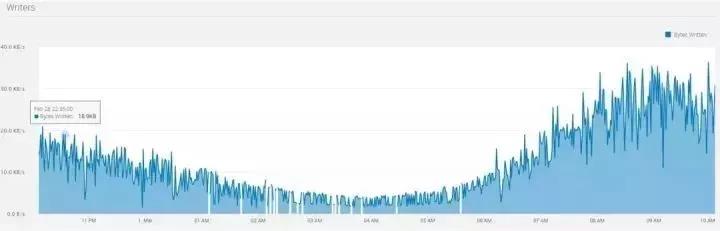
图3: 出租车数据流量记录
由上图我们可以观察到,数据流量在早上4点左右处于谷点,而在早晨9点左右达到峰值。峰值流量的写入字节数大约为谷点流量的10倍。我们将Stream的伸缩规则配置为上述规则2(基于大小的伸缩规则)。
相对应地,Stream的Segment热点图如图4所示动态变化:
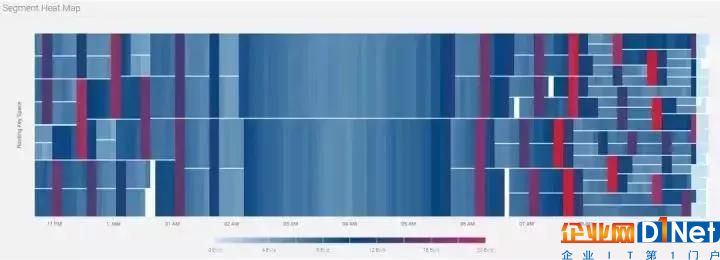
图4: Segment 热点图
从上图可以看出,从晚11点至凌晨2点,Segment逐渐合并;从早晨6点至10点,Segment逐步拆分。从拆分次数来看,大部分Segment总共拆分3次,小部分拆分4次,这也印证了流量峰值10倍于谷底的统计值(3
我们使用出租车行程中的出发点坐标位置来作为路由键。当高峰来临时,繁忙地段产生的大量事件会导致Segment被拆分,从而会有更多的读客户端来进行处理;当谷峰来临时,非繁忙地段产生的事件所在的Segment会进行合并,部分的读客户端会下线,剩下的读客户端会处理更多地理区块上产生的事件。
本章总结:
本期内容我们重点介绍了Pravega的动态伸缩机制。它可以让应用开发和运维人员不必关心因流量变化而导致的分区变化需要,无需手动调度集群。分区的流量监控和相应变化由Pravega来进行,从而使流量变化能够实时而且平滑地体现到应用程序的伸缩上。独立伸缩机制使得生产者和消费者可以各自独立地进行伸缩,而不影响彼此。整个数据处理管道因此变得富有弹性,可以应对实时数据的不断变化,结合实际处理能力而做出最为适时的反应。
截至目前,我们已经花了3个篇幅(第一期、第二期)详细了Pravega,相信你对它已经有了一定的了解,话说百遍不如自己跑一遍,在下一期的“IoT前沿”中,我们就将为大家带来实战演练,介绍Pravega的部署方式。
欢迎大家持续关注,如何你有疑问,可在下方留言或知乎号上(见下方二维码)找到我们。下一期见~

扫码关注知乎号
你和戴尔易安信专家只有一条网线的距离~








 京公网安备 11010502049343号
京公网安备 11010502049343号