


为了解决这个问题,用户可以用自己的定制文档来增强大型语言模型。本文将展示一个框架,通过使用文档嵌入为用户自己的数据提供ChatGPT或GPT-4(或任何其他大型语言模型)的场景。
为大型语言模型提供场景
大型语言模型对场景敏感。如果用户给它一个简单的提示,就会根据它们从训练数据中提取的知识做出反应。但是,如果在提示符前添加自定义信息,则可以修改它们的行为。
例如,如果用户问ChatGPT这个问题,“使用运行率的风险是什么?”,它会提供一个很长的答案。
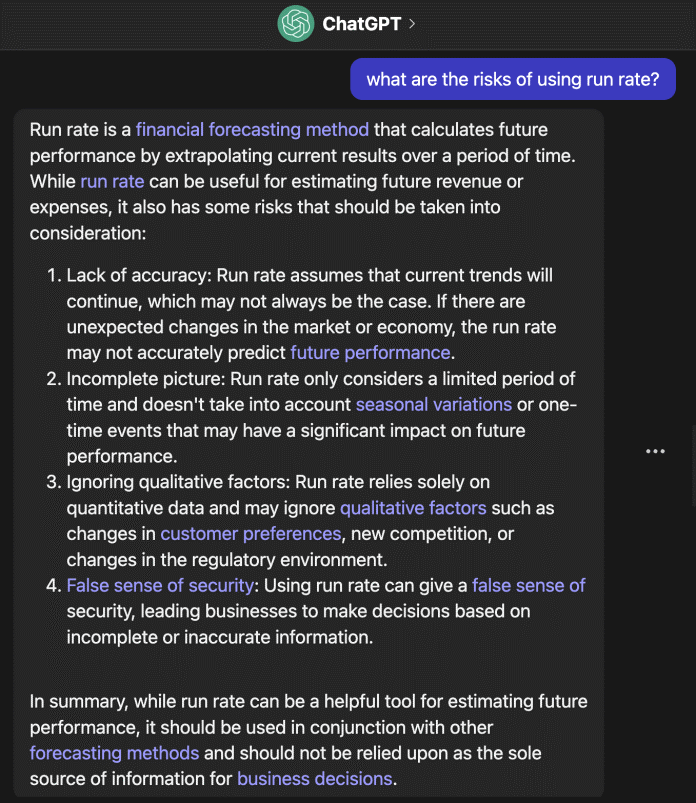
ChatGPT给出的一般性答案
但是,用户可以提示ChatGPT根据特定文档提供答案。在下面的例子中,问了ChatGPT同样的问题,但是在提示符前加上了“根据以下文档回答我的问题”,后面是来自Investopedia公司的一篇关于运行率的文章。这一次,ChatGPT提供了一个不同的答案,从文章的文本中提取。

从文档中给出ChatGPT场景

ChatGPT根据文档场景进行响应
这种技术的价值是显而易见的,特别是在场景非常重要的应用程序中。但是,人工向提示添加场景是不切实际的,特别是有数千个文档时。
假设企业有一个网站,该网站有数千个页面,其中包含有关金融主题的丰富内容,并且希望创建一个基于ChatGPT API的聊天机器人,以帮助用户浏览这些内容。用户需要一种系统的方法来将其提示与正确的页面相匹配,并使用大型语言模型来提供场景感知的响应。这就是文档嵌入的用武之地。
使用嵌入捕获语义
在进入嵌入之前,先为聊天机器人创建一个高级框架:
1.用户输入提示。
2.检索与提示相关的最佳文档。
3.创建一个新的提示,其中包括用户的问题以及文档中的场景。
4.给语言模型提供新制作的提示。
5.将答案返回给用户。
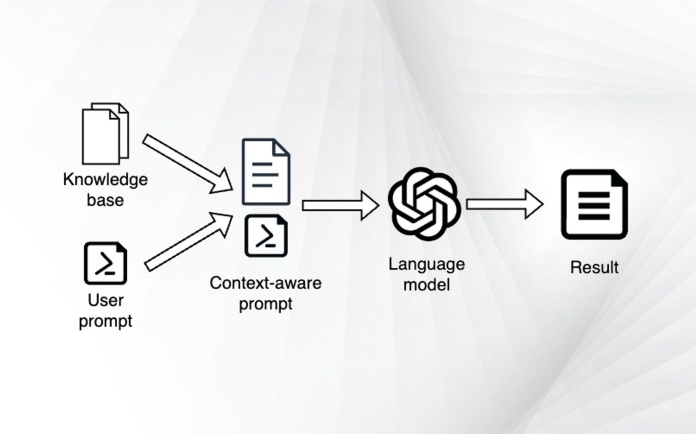
为ChatGPT提供场景
从编程的角度来看,除了第2步之外,这个过程非常简单。那么如何决定哪个文档与用户的查询相关?一个基本的答案是使用经典的索引和关键字搜索。更好的解决方案是使用嵌入。
嵌入是一个数字向量(一个数字列表),它捕获了一条信息的不同特征。嵌入的维度越多,它可以学习的特征就越多。
用户可以对不同类型的数据使用嵌入。例如,在与图像相关的任务中,嵌入可以表示不同物体的存在与否,不同颜色的强度,不同物体之间的距离等。
在文本中,嵌入捕获文本的不同语义方。例如,单词嵌入可能包含有关单词是否与城市或国家、动物物种、体育活动、政治概念等相关的信息。在同样的意义上,短语嵌入创建了单词序列内容的数字表示。通过测量两个嵌入向量之间的距离,可以得到它们对应内容的相似度。
通过训练机器学习模型(通常是深度神经网络)在大量示例数据集上创建嵌入。在许多情况下,嵌入模型是用于最终应用(例如,文本生成或图像分类)的相同模型的修改版本。

为文档创建嵌入数据库
要将嵌入集成到聊天机器人工作流中,用户需要一个包含所有文档嵌入的数据库。如果文档已经在数据库中以纯文本形式存在,那么就可以创建嵌入了。如果没有,需要使用某种技术,例如使用Python Beautiful Soup的网页抓取来从网页中提取文本。如果其文档是PDF文件,例如研究论文,则需要从中提取文本(可以使用Python PyPDF库执行此操作)。
要为文档创建嵌入,用户可以使用在线服务,例如OpenAI的嵌入API。用户向API提供文档的文本,它将返回其嵌入。OpenAI的嵌入有1536个维度,是最大的嵌入之一。或者可以使用其他嵌入服务,例如Hugging Face或用户自己的自定义Transformer模型。
一旦有了嵌入,就必须将它们存储在“矢量数据库”中。向量数据库专门用于嵌入,并提供不同的功能,例如基于不同度量(欧几里得距离,余弦相似度等)的查询。
Facebook公司的Faiss是一个流行的开源矢量数据库,它提供了一个丰富的Python库来托管用户自己的嵌入数据。另外,可以使用Pinecone,这是一个在线矢量数据库系统,它抽象了存储和检索嵌入的技术复杂性。
现在,用户已经拥有了创建针对自己的专有数据定制的大型语言模型应用程序所需的一切。现在可以像下面这样改变应用程序的逻辑:
1.用户输入提示
2.为用户提示创建嵌入
3.在嵌入数据库中搜索最接近提示嵌入的文档
4.检索文档的实际文本
5.创建一个新的提示,其中包括用户的问题以及文档中的场景
6.给语言模型提供新制作的提示
7.将答案返回给用户
8.奖励:提供一个链接到文件,用户可以进一步获取信息

使用嵌入和矢量数据库检索相关文档
为了避免人工创建整个工作流,用户可以使用LangChain,这是一个用于创建大型语言模型应用程序的Python库。LangChain支持不同类型的大型语言模型和嵌入式,包括OpenAI、Cohere、AI21Labs以及开源模型。它还支持不同的矢量数据库,包括Pinecone和FAISS。它为不同类型的应用程序提供了现成的模板,包括聊天机器人、问答和活动代理。
关于嵌入的重要考虑
为了正确使用大型语言模型的嵌入,需要记住以下事项:
·在用户使用的嵌入框架中保持一致:确保在整个应用程序中使用相同的嵌入模型。例如,如果用户选择OpenAI嵌入,需要确保使用相同的API和模型来创建文档嵌入、用户提示嵌入和搜索矢量数据库。否则,将得到不一致的结果。
·令牌限制:每个大型语言模型都有令牌限制。例如,ChatGPT可以保留多达4096个令牌的场景。GPT-4有8000个和32000个令牌限制。许多开源模型限制为2048个令牌。这包括文档场景、用户提示和模型响应。因此,用户必须确保场景数据不会填满大型语言模型的内存。一个良好的经验法则是将文档限制为1000个令牌。如果文档比这个大,可以将其分成几个块,每个部分之间有一点重叠(大约100个令牌)。
·使用多个文档:用户的回复不必局限于单个文档。可以检索嵌入与提示符相似的几个文档,并使用它们来获取响应。为了确保不会遇到令牌限制,可以为每个文档分别提示模型。
为什么不微调大型语言模型呢?
为什么不用微调大型语言模型来代替场景嵌入?微调是一个很好的选择,使用它取决于用户的应用程序和资源。通过适当的微调,用户可以从大型语言模型中获得良好的结果,而无需提供场景数据,从而降低了付费API的令牌和推理成本。然而,微调可能是昂贵和复杂的。使用场景嵌入是一种简单的选择,能够以最小的成本和努力实现。
最后,如果用户有一个良好的数据收集管道,可以通过根据其目的的微调模型来改进系统。
关于企业网D1net(www.d1net.com):
国内主流的to B IT门户,同时在运营国内最大的甲方CIO专家库和智力输出及社交平台-信众智(www.cioall.com)。同时运营19个IT行业公众号(微信搜索D1net即可关注)
版权声明:本文为企业网D1Net编译,转载需在文章开头注明出处为:企业网D1Net,如果不注明出处,企业网D1Net将保留追究其法律责任的权利。








 京公网安备 11010502049343号
京公网安备 11010502049343号