



正当世界都在关注 Google 与美国五角大楼合作,道德压力迫使 Google 公开表示将不再与美国国防部续约,但人工智能衍生的争议又岂是发展 AI 武器一案而已。人工智能已经不是一项技术平台的问题,而是应该如何使用的问题。
今年 4 月,麻省理工学院媒体实验室(The MIT Media Lab)的一个三人团队:联手创造了一个人工智能——诺曼(Norman)。不过,这个与惊悚片大师希区柯克的经典电影《惊魂记》中的变态旅馆老板诺曼·贝兹(Norman Bates)同名的 AI,是全世界第一个精神变态者人工智能(World's first psychopath AI.)。另外一提,如果你对于 MIT Media Lab 在去年万圣节推出 AI 与人类合写恐怖故事的人工智能 Shelley 还有印象的话,同样是来自于这个团队的项目。
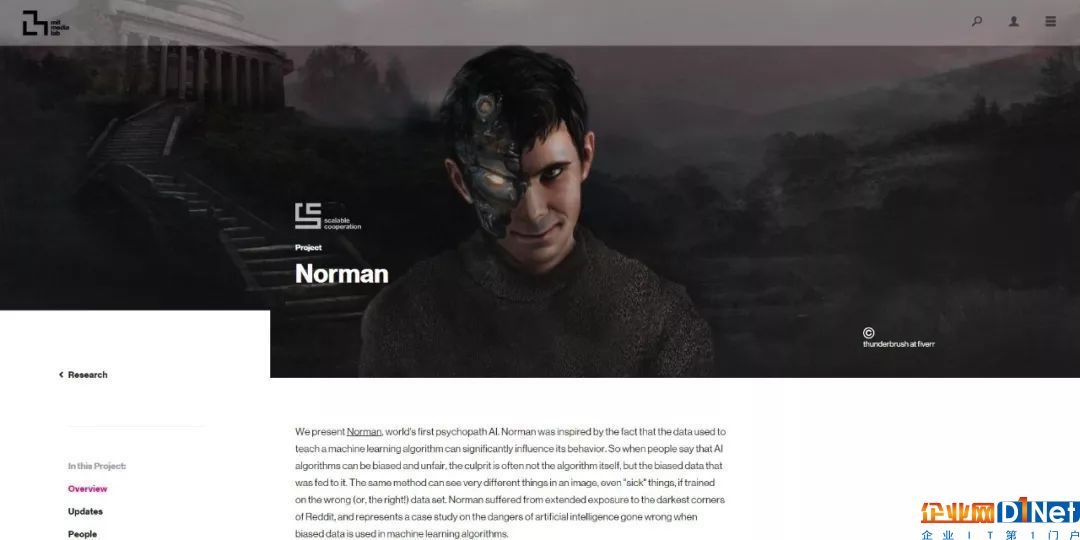
图|MIT Media Lab 打造了全球第一个精神变态者人工智能——诺曼

图丨MIT Media Lab 的三人团队
官方链接:http://norman-ai.mit.edu/
当然,MIT 作为全球最领先的学术殿堂之一,并不是真要把恐怖片的情节搬到现实生活中,他们的目的是告诉全世界必须正视一件事:用来教导或训练机器学习算法的数据,会对 AI 的行为造成显著影响。也就是说,有偏差、偏见的数据就会可能训练出带有偏差/偏见的人工智能,预测或分析出带有偏差/偏见的结果,就像不少科学家就以“garbage in, garbage out”这句话,贴切形容“数据和人工智能的关系”。
MIT Media Lab 指出,当人们谈论人工智能算法存在偏差和不公平时,罪魁祸首往往不是算法本身,而是带有偏差、偏见的数据。尽管在训练模型时是使用同样的方法,但使用了错误或正确的数据集,就会在图像中看到非常不一样的东西。
诺曼是一个会生成图像文本描述的深度学习方法,当诺曼看到一张图像,就会自动产生文字或标题来解释它在该图像中看到了什么,但特别的地方在于,MIT Media Lab 使用 Reddit 论坛上充斥着令人不安的死亡、尸体等暗黑内容的子论坛(subreddit)的数据来训练诺曼,然后,他们将诺曼与一般性的图像标题神经网络一同进行了罗夏墨迹测验(Rorschach Inkblots)。

图丨瑞士精神科医生、精神病学家罗夏
罗夏墨迹测验是由瑞士精神科医生、精神病学家罗夏(Hermann Rorschach)创立,最著名的就是投射法人格测试,受试者通过一定的媒介建立起自己的想象世界,因此被视为是一种个性测试法。两相对照下,有了令人毛骨悚然的发现。
这张图你看到了什么?
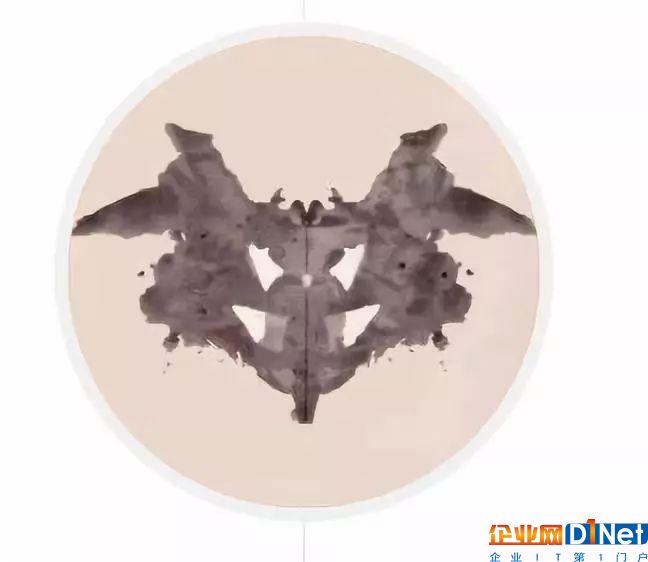
一般 AI :一群鸟坐在树枝上
诺曼:一名男子触电而死
那这几张呢?

一般 AI:近拍一个插有鲜花的花瓶
诺曼:一名男子被枪杀

一般 AI:几个人站在一起
诺曼:男人从落地窗跳下来

一般 AI:小鸟的黑白照
诺曼:男人被拉进面团机里
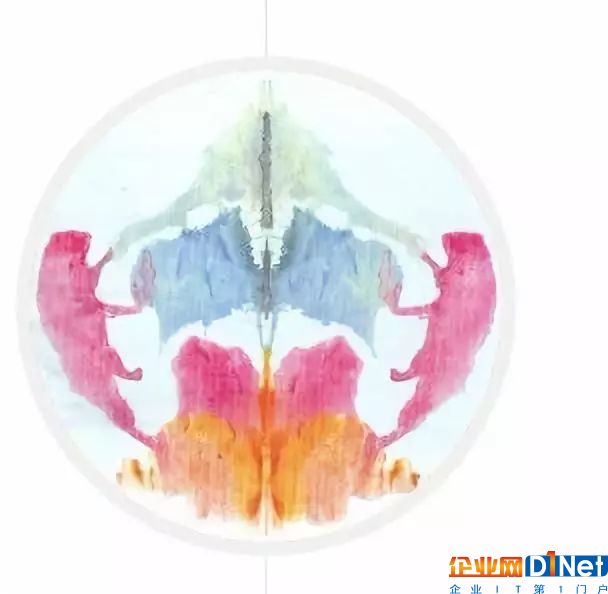
一般 AI:一个人举着一把雨伞
诺曼:男子在尖叫的妻子面前被枪杀
从墨迹测验可以看到,一般 AI 看到的都是较为常态或乐观的意象,例如小鸟、鲜花,但诺曼看到的多偏向冲突性、死亡场景,像是被枪杀、触电而死。在诺曼项目的官网(http://norman-ai.mit.edu/)可以看到更多测试结果。
诺曼代表的是一个案例研究:当有偏差的数据被用于机器学习算法时,人工智能就会走偏、甚至走向危险的道路。诺曼的开发者之一、 MIT Media Lab Scalable Cooperation 助理教授 Iyad Rahwan 接受 BBC 采访时就指出,诺曼 AI 能反映出非常黑暗的事实,说明人工智能可以学习这个世界中的恐怖现实。不过,诺曼项目的团队设立了一项功能,可以让人们回答自己所看到的世界,可能会帮助诺曼修复自己,把它从暗黑世界里拯救出来。

图丨人们回答自己所看到的世界可能会帮助诺曼修复自己
身处在 AI 的暗黑面,诺曼并不孤单
诺曼可以说对外展现了“网络黑暗角落”的数据对 AI 世界观造成影响的一个研究案例,但诺曼并不是唯一,现实生活中的 AI 若受到有缺陷数据的训练,均可能产生类似负面状况,用了带有偏见的数据,训练出带有偏见的模型、预测出带有偏见的结果,加速传播或放大某些族群对另一个族群的偏见,例如种族歧视、性别歧视、对 LGBT 人群的歧视等。
除此之外,AI 军事应用,以生成对抗网络(GAN)创造假视频、假图像也是相关技术遭滥用的案例。
谷歌参与美国国防部底下代号为 Maven 的项目,全名称为“算法作战交叉功能工作小组”(Algorithmic Warfare Cross-Functional Team,AWCFT),旨在通过设计好的算法取得战斗优势,例如为打击 ISIS 恐怖组织,美军内部已设立一专门小组,负责加速解析无人机每日例行性收集的照片与视频,其中合作的对象不只是谷歌一家。

有时候,军力常被误以为是国力的一种象征,在这种权力欲望的驱使下,加入 AI 军备赛的国家可能只会更多。
日前,印度媒体就报道,为了不在发展 AI 监控及防御系统的领域落后,印度已成立一个 17 人、发展智能武器的特别小组,印度国防部秘书 Ajay Kumar 对外说明成立此 AI 特别小组的原因在于,“世界正走向人工智能驱动的战争,印度正采取必要措施来准备武装实力”。印度总理 Narendra Modi 甚至强调人工智能和机器人等新兴技术可能是未来防御和进攻能力的关键,必须为这场新的军事变革做好准备,印度将努力通过在信息技术领域的领先地位来取得优势。
“自主武器确实很可怕,”积极推动 FAT ML 的卡内基梅隆大学(CMU)教授 Zachary Lipton 接受 DT 君专访时表示,“如同我们上述讨论的,目前的机器学习系统无法解释道德需求,它们不知道什么是种族主义,不知道什么是杀人。它们只是在做简单的任务,如脸部识别,他们的输出来自于某些人类写进去的规则,而允许这样的系统杀人是不负责任且疯狂的。”Zachary Lipton 说。

图丨卡内基梅隆大学(CMU)教授 Zachary Lipton
这一波的人工智能风潮来自于机器学习领域取得了很大的进展,如前所述机器学习除了能做好事,也能做恶事,用在武器可以杀人,用 GAN 制作假图像、假视频,可以骗人,用带有偏见或偏差数据及算法,可以歧视人。
因此,有一群来自行业界及学界的 AI 专家及研究者向全球大声呼吁,在发展人工智能的过程中,不应单纯以技术本位为出发,还必须重视三个关键:公平(Fairness)、责任(Accountability)、透明性(Transparency),所以,FAT ML 旨在打造公平、责任、透明的机器学习算法,希望人工智能用来做良善的事,而非伤害人类。
技术中性,人心操之
像是微软纽约实验室中就设立了一个 FATE 小组,FATE 代表四个英文字 Fairness(公平)、Accountability(责任)、Transparency(透明)和 Ethics(道德)。
其实涉入五角大楼争议的谷歌,内部也设立了一个“人与 AI 研究”(People + AI Research Initiative)——PAIR 项目,由谷歌大脑的两位科学家 Fernanda Viégas 与 Martin Wattenberg 带领,目标是研究和设计人与 AI 系统有效互动的方式,以及发展以人为中心的人工智能,除了发表研究成果,还提供研究人员和专家使用的开源工具。

不只是产学界在推动,英国政府不久前出台了官方的发展 AI 原则,第一个准则就是:AI 应该为了人类良善和人类福祉而开发。准则二:人工智能应该在可理解和公平的原则下运作。准则三:人工智能不应该被用来削弱个人、家族或社群的数据权或隐私权。准则四:所有公民都有权接受教育,使他们能够在精神上、情感上和经济上与人工智能一起成长。准则五:不应该使用人工智能来发展能伤害、摧毁或欺骗人类的自主力量(autonomous power)。
坏角色好识别,但也得注意无心之过
不过,“除了这些坏角色之外,我同样担心人们可能在无心之下做出不好的事,而且他们自己并不知道,”谷歌云人工智能产品线主管 Rajen Sheth 如是说。
为什么说是无心的过错?就算对于人工智能只有简单了解的人都知道,数据可以说是训练机器学习模型的基础,喂给机器什么样的数据,就会训练出什么样的模型,当开发者或技术人员使用带有偏见的数据,就可能训练出带有偏见的模型,分析或预测带有偏见的结果,“garbage in, garbage out”。
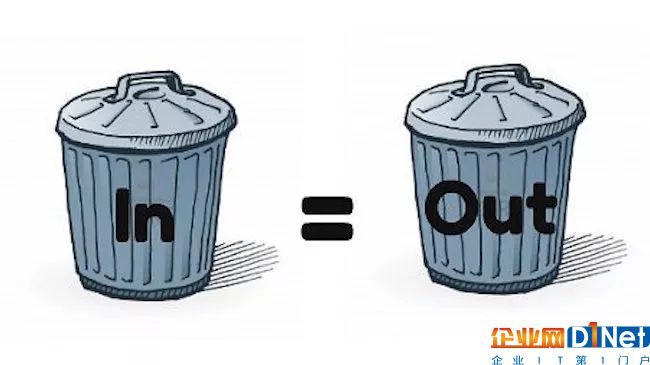
相信在大多数的科学家或技术人员的心中,都存在“利用科技让社会变得更好”这样的价值观,但偏见、刻板印象有时涉及了难以量化定义的感觉、看法,如果研究者本身没有察觉或是没有意识到这类问题,就很难完全避免将偏见带进算法里。
在谷歌研究自然语言处理(NLP)的科学家 Daphne Luong 就表示,正确地校准标签,在机器学习是非常关键的,有些数据集其实并不平衡,像是维基百科上的数据,“他”(He)出现的次数远比“她”(She)来得多。
知名的独立调查机构 ProPublica 就多次揭露算法带有偏见的问题,例如评估罪犯再犯率风险的软件,往往会将黑人标记为在未来犯罪有更高的风险,另外数十家大企业包括亚马逊、Verizon、UPS 等,在 Facebook 投放招聘广告时利用算法排除年纪较大的员工,一些专家就质疑此种做法可能已经触犯了美国的“就业年龄歧视法”(Age Discrimination in Employment Act),该法禁止企业在招聘或就业方面对 40 岁以上的人存有偏见。
什么是公平的算法?应把道德摆在第一位
对于什么是机器学习算法的公平性,Zachary Lipton 认为:“首先,应该把‘道德’摆在第一位,道德是指导我们如何行事的原则,它涉及了行动及其后果。”
当然,人类并非所有的行动都具有道德意义,像是每天早上我们决定穿哪双鞋出门,“但是,有些决定会产生重大后果,而且我们希望能避免某些行为模式,例如,避免某些族群拥有特权,以及避免他们利用特权为其他人群做决定。”
Zachary Lipton 指出:“当人类希望使用基于机器学习的系统进行自动化决策,机器学习就会开始接触道德规范”,当这些决定涉及某些伦理敏感领域时,就可能出问题。同时,“这里最大的问题是,现实世界中大部分的机器学习系统都是基于监督式学习(supervised training),它不知道行动的意义,它只是试图通过一系列的范例来猜测正确的答案。”
所谓的监督式学习是通过人类已标注的数据,学习或建立出一个模型。举例来说,银行在评估是否放款给某些人时,模型可能会看到一个由历史贷款申请人组成的数据集,每个数据组都与一个标签配对。每一笔申请可能带有一长串的属性,像是收入、职业、财务历史、想借贷的金额等。机器学习模型使用上述属性尝试找出一个公式,以预测这笔贷款是否会违约。银行就使用这种模式,决定接受低违约率(低于某个阈值)的申请者作为客户,并且拒绝其他人的申请。

那么,在令人担心的敏感属性(sensitive attribute)部分,例如性别歧视或种族歧视,我们可能认为在训练模型时,忽略这些信息是可以接受的(We might think it's ok to just ignore this information when training the model.)。但是,问题在于敏感属性、不敏感属性(insensitive attribute)和标签(label)通常是相关连的,模型并不知道它们是相关的机制,它不知道什么时候 A 组在工作上的表现比 B 组更好,是根据教育背景还是歧视?目前机器学习的多样性,还无法推论行为或其后果,因此从根本上说,它无法作出任何种类的道德区分。
这个世界没有魔法,也没有银子弹
DT 君进一步询问 Zachary Lipton,机器学习模型很可能在无心的情况下发展出有偏见的模型,从科学家的角度来看,有方法可以避免这个问题?如何过滤掉训练数据集中的偏见或刻板印象?
他先是提醒:“偏见”这两个字有时被不精确地使用,所以在阅读讨论算法偏见的论文或研究时,要特别观看内容及定义,以免被时被不精确地使用。
接着他回答了上述的问题,他很直白地说:“简短的回答是:没有(Short answer: no)。有很多的期望,但事实是,没有银子弹(silver bullet)。”
“那么你可能会说,机器学习 100% 都是刻板印象”,换句话说,机器学习从来不知道“为什么”两件事会合在一起,只知道它们在统计上是相关的,但它无法区分某些决定是基于合理基础,或是某些不良的关联是来自社会上的歧视。“有很多想去除模型偏见的神奇想法,在这个领域没有可以迅速解决困难的有效方法。这个世界没有魔法,也没有可使所有问题都消失的“公平算法”,只有仰赖“批判性思维(critical thinking)”!”他强调。

同样重视人工智能在公平、责任、透明之下发展的亚马逊 AWS 深度学习首席科学家 Anima Anandkumar 则对 DT 君表示,过去谈人工智能很多人只会在意“正确性”,但随着机器学习引发的争议,证明还得关心更多,仅管她坦言在推广 FAT ML 遇到的第一个问题就是难以定义,每个人对于公平、责任、透行可能有不同的见解,不过,没有标准答案不代表没有解决方案,如果要让机器学习往良善的方向前进,最关键的作法就是“团队和社区的多样性”。
图丨亚马逊 AWS 深度学习首席科学家 Anima Anandkumar
她举例,包括数据多元性、研究团队中成员的多元性,包括性别、专业领域如社会学家、心理学家等人的观点、年龄,甚至是工具的多样性,“人工智能不只是科技人的事,必须从科技的圈子跳出去,和其他领域的专家一起合作,多元性越高,就越可能避免问题产生。”人工智能在未来对人类社会的影响只会更深且广,因此还需要透过教育让学生尽早了解人工智能可能产生的问题及影响,以及学习使用相关工具,才有机会让新世代的每个人都能取用人工智能。
因此,从长远来看,Zachary Lipton 认为,人类需要做两件事。首先,要非常小心如何以及在哪里使用机器学习,来做出某些相应的决定。其次,我们需要监督式学习之外的东西,并且追寻更了解创建数据的世界以及自动化行为对世界的影响。
如同 Zachary Lipton 的看法,不少学者或科学家都投入发展非监督式学习(unsupervised training)的研究,在进行非监督式学习的模型训练时,使用不带任何标签的数据,由算法自行分类、识别和汇整数据,通过减少人为介入,相对能够消除任何有意识或者无意识的人为偏见,进而避免对数据产生影响。Facebook 首席科学家 Yann LeCun 就曾公开指出,非监督式学习是突破 AI 困境的关键。

任何科技的诞生都有好的一面,以及坏的一面,Google Research Applied Science 部门主管 John Platt 举例:“烦人的垃圾电子邮件从 80 年代就有了,一直到 1997 年左右,才有第一个邮件过滤器的问世”,而且加入机器学习后,更有效的阻挡垃圾邮件,每天都有新的 AI 使用问题诞生,但每天也会有更多解决问题的工具出现,就像上述的假视频,除了 DARPA,还有许多研究机构也在开发可以检测假视频的工具,像是卡内基梅隆大学软件工程研究所的计算机科学家团队、麻省理工学院团队,都已经投入该领域数年。
为善与作恶、真实与虚假、公平与偏见,是人工智能的一体两面。阻恶、打假、去偏,就成了新的任务。没人知道未来会如何,但是,预测未来的最好方法,就是靠自己去创造。






 京公网安备 11010502049343号
京公网安备 11010502049343号