



图丨高通已经把AI 当作未来移动平台的重点发展方向。
随后的骁龙835 则是引入了神经处理 SDK,并与Google 和Facebook 进行了深入合作,针对两者提供的框架进行了优化,在终端侧支持TensorFlow 和Caffe2。它们曾经都是通常在云端运行的框架。一旦网络受到了训练,开发者就可以从骁龙移动平台中选择合适的内核运行。另外,离线工具可以在目标运行前,对模型进行转换、优化、量化。
当然,软件再怎么优化还是不如硬件,835 的AI 整体计算性能仅能达到A11 或者是麒麟970 内建NPU 的几分之一,且能耗表现明显较差。
但高通还是往前迈进了一步,那就是NPE 开发环境已经不再封闭,而是提供给广大的第三方AI 应用开发者,NPE 也理所当然的支持主流深度学习框架,包含TensorFlow、Caffe 等,而最近才发表的TensorFlow Lite 及Facebook 与微软合作推出的ONNX 也同样在支持之列。高通也期待借此能在AI 的路上后发先至,甚至凭借更完备的开放式开发环境反超苹果和华为。
Hexagon 685 DSP 过去都是针对影像或音频处理做加速使用的单元,但是到骁龙845,通过额外增加的向量处理单元,配合原本可程序设计的特性,已经可以很好的应对现在AI 计算环境中的各种框架执行需要,当然,DSP 的计算能效虽不如NPU 之类的ASIC 方案,但其可弹性配置的优点,以及高通针对开发环境的优化,仍能达到相当不错的表现。
不过与华为、苹果不同,高通认为考虑到手机系统功耗限制,训练还是在云端为佳,因此整套 NPE 方案还是以推理为主,并且集中在图像处理以及语音识别等功能上,当然,未来还是有改变的可能。
为扩大高通的AI 生态,就不能只守在高端芯片产品,过去作为中端方案的高通Snapdragon 600 系列在AI 性能方面远远落后于高端的800 系列,因此在相关手机方案上几乎没有厂商将AI 功能嵌入进去,为此,高通推出的Snapdragon 700 系列算是终于补上了这道缺口,其AI 计算性能要比600 系列高了225% 以上,已经相当接近高端方案的水平,而客户对此也相当欢迎,毕竟高通还是市场上最主流的中高端方案供应者,若能够在中端产品增加更多AI 附加功能,那对于产品的销售还是有相当好的帮助的。
高通确立AI 生态优势,力抗华为与苹果
AI 已经成为手机最热门的话题应用,为了确保高端手机的使用体验能更贴近用户,在不论照相功能、语音服务,以及其他智能服务上,具备高性能AI 加速功能已经是基本要求,但是在开发环境上,如果对开发者不够友善,那么就很难建立生态。
对此,高通提供开发者一套神经处理SDK,它可以支持Android NN 环境。也同时支持了Hexagon NN环境,如果开发者选择使用Hexagon DSP 来做开发,Hexagon NN 库就可以专门针对某一内核进行优化。所有这些功能为开发者带来极大的灵活性,并有助于他们实现性能最大化。这也说明,智能手机AI 体验不能仅仅依靠一个特定的内核,更重要的是需要多种架构、多种工具。
高通过去手机方案的开发工具包都只针对其客户发放,并没有考虑到第三方软件开发者的需求,虽然高通平台同样能支持一般标准开发平台,比如说Android 开发平台,但这么一来就无法完全发挥高通平台在硬件设计上的独到之处,而 NPE 针对第三方开发者的友善设计算是高通相当明智的策略转变,NPE 在应用开发上的优势,以及在高通平台的基础渗透率极为庞大的状况下,未来成为手机AI 的主导平台也不会令人意外。
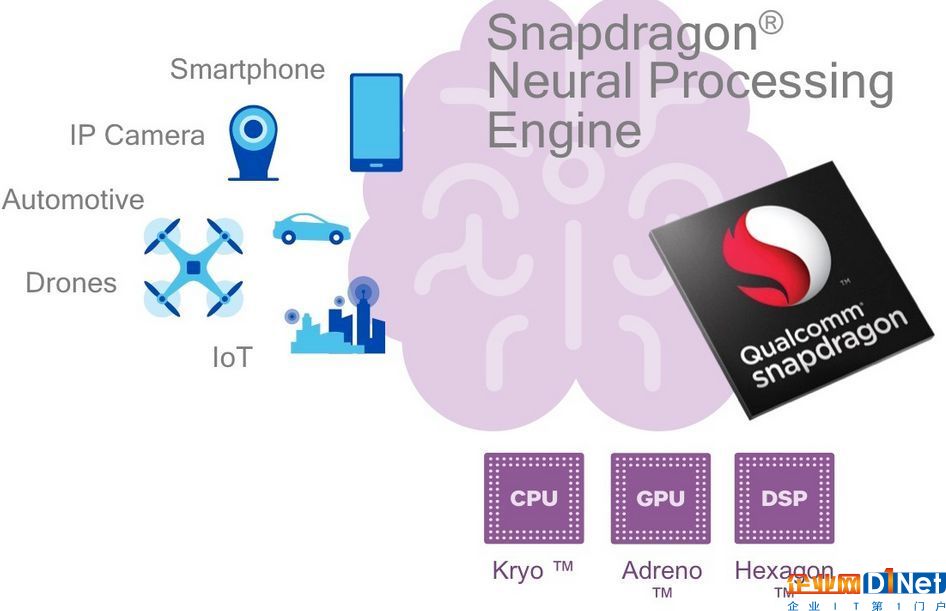
图丨 NPE 作为高通主推的开发工具包,已经面向第三方开发者发放
推动神经网络算法的演进,让人工智能更贴近实用
当然,在硬件开发环境方面的改善,高通做了不少的努力,不过在这些看的见的方案的背后,其实高通花了更多的心力。

图|高通技术副总裁韦灵思 (Max Welling)
高通技术副总裁韦灵思(Max Welling) 在接受DT 君的专访时表示,高通不只在方案上推动AI 功能的演进,同时也积极改善神经网络算法的效率。由于传统卷积神经网络使用了太多的内存、计算能力和能源,怎样应用到移动终端上,是急需改善的项目之一。
此外,神经网络不具备旋转不变性。我们都知道把狗上下颠倒过来,人类依然还能辨认是狗,但神经网络是不知道的,它需要从很多人工叠加的数据中学习才能识别。高通最近发表的一篇论文获得了ICLR 2018 年度最佳论文奖,其中就谈到了如何在卷积神经网络上构建旋转不变性。
另一个神经网络需要提高的方面是,它不能对“不确定性”这一特征进行量化,韦灵思认为这点非常重要。如果使用者驾驶一辆自动驾驶汽车来到一个新的城市,而这台汽车没有接受过与新城市相关的训练。在这种情况下,自动驾驶汽车需要意识到它对于新城市的疑惑和不知所措,然后自动停下来或把驾驶权交还给用户,而不是很有信心地继续向前。
简单地说,人工智能需要知道自己的局限在哪里,而目前神经网络在这一点上还不够完善。
神经网络还有一个缺点,那就是它很容易被输入侧轻微的改变所欺骗,如对抗样本(Adversarial Examples),其识别物体不具备人类大脑的鲁棒性(Robustness)。例如,我们通过改变图片中的几个像素就能让算法完全改变其对目标的分类,将狗识别成企鹅,而人类并不会被这些轻微的改变所欺骗。这也是我们需要解决的问题之一。
韦灵思表示,为应对这些挑战,高通开展了大量的工作,当然,如果以高通移动方案的AI 功能来看,最重要的还是在能耗表现方面。受人类大脑的启发,高通早在超过十年前就已经开始了脉冲神经网络的研究,这也是实现低功耗计算的一种方法。
回到今天,同样受人脑的启发,高通正考虑利用噪声来实现深度学习方面的低功耗计算。韦灵思提到,人脑其实是一个充满噪声的系统,它知道如何处理噪声。若能妥善利用噪声,将可为神经网络带来益处。
在专业领域,这种方法称为贝叶斯深度学习,这也是实现低功耗深度学习的重要基础性框架。通过贝叶斯深度学习,我们能把神经网络压缩得更小,使其可以更高效地运行在骁龙平台上。我们还可以通过使用这一框架,量化我们需要进行的计算处理的比特位。
当然,DT 君也提出关于目前也有不少针对深度学习以及神经网络模型的压缩技术推出,这与高通目前走的贝叶斯深度学习压缩方法有何差别的问题。
韦灵思表示,针对神经网络的压缩方式有不同的技术类型可以选择,比如说剪枝法,或者是高通选择的贝叶斯算法,不同的方案可以很好的处理不同的应用场景,但是在移动领域中,高通的作法还是能够得到更好的结果。
韦灵思进一步解释,使用贝叶斯框架进行压缩与量化还可以解决许多其他问题。比如说,若神经网络只进行过面向某一场景的训练,例如一辆自动驾驶汽车只接受过某一城市的相关训练,现在这台汽车来到另一个新的城市,你可以使用贝叶斯深度学习进行泛化。
就开发思路而言,能够对数据做出解释的最小、最简单的模型即为最适合的模型,这就是奥卡姆剃刀。当我们对一个模型进行裁剪,这对这个模型是件好事。
另外,贝叶斯学习还可以帮助我们产生置信估计,即量化神经网络的不确定性。当我们加入噪声,传播至预测模型上,从而产生预测的分布区间,由此完成对预测置信度的量化。
最后,贝叶斯学习可以更好的帮助AI 计算环境不轻易遭受对抗攻击,即通过输入侧的轻微改变来得到不同的预测结果。它也有助于保护用户的个人隐私,因为数据信息可以转换为模型参数甚至可以进行重构,使得数据具有隐私敏感度。所以说通过加入噪声,可以很好地帮助我们保护隐私。
总体而言,贝叶斯深度学习可以很好地解决深度神经网络所面临的诸多挑战。
韦灵思最后也提到,由硬件、软件和算法构成的生态系统对我们来说至关重要。高效的硬件将不断演进,以适应在人工智能领域出现的全新算法。如何在硬件上更高效地运行卷积神经网络,以及为高效运行神经网络而开发更高效的新硬件是不变的趋势。在算法方面,确保算法在骁龙平台上的高效运行需要通过软件工具来实现,也就是骁龙神经处理SDK。大家可以将软件看成是连接硬件和算法之间的桥梁。
比如说开发者在骁龙平台上构建你最喜欢的模型,或进行你最喜欢的人工智能测试,当你将模型放到神经处理SDK 中,这些可用的软件工具将帮助开发者进行压缩和量化,从而确保开发者的模型或测试能在骁龙平台上高效运行。








 京公网安备 11010502049343号
京公网安备 11010502049343号