


作为国内最优秀的AI芯片公司,深鉴科技被以3亿美元的价格卖给FPGA巨头赛灵思。过去两年,深鉴科技是国内AI芯片领域冉冉升起的一颗明星。这家2016年3月成立的初创公司目前已完成三轮融资,投资方包括金沙江创投、蚂蚁金服、三星风投、赛灵思、联发科等知名机构和公司。
据媒体报道,其估值远超过10亿美金。如今以3亿美元卖出,并且据称核心团队要锁定4年内不得离开赛灵思。难道深鉴科技被贱卖?当然没有!这是因为中国真正优秀的企业太少,而追逐的资本太多,优秀企业的估值已经到了完全没有理性的地步。如果这些企业在美国,估值会萎缩数倍以上。
FPGA已经不是FPGA,更接近于ASIC
不是短期盈利无望,而是长期盈利无望,卖身给FPGA厂家肯定是最明智的选择。在大部分人眼里,FPGA缺乏技术含量,纯粹靠专利建立起护城河,FPGA只是个躯壳,算法才是灵魂。
是深鉴让FPGA获得灵魂。果真如此的话,那估值就不是3亿美元。实际上声称有能力做机器学习算法的公司据说超过3000家,而大规模生产FPGA的独立厂家全球仅Xilinx一家。
算法应该说像人的视觉系统,FPGA则是人的大脑和躯壳。现在的FPGA早已不是当年的简单地把寄存器和LUT整合在一起的白纸了,而是越来越像ASIC,或者说SoC。现在的FPGA都包含了复杂的接口资源,收发器资源,存储器资源,有些则直接加入了多个ARM内核。单纯的FPGA几乎不存在了。
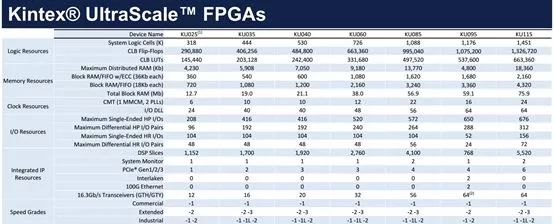
以深度学习、高性能运算、图形科学领域最常见的Kintex FPGA来看,国内百度、腾讯、阿里都采用了KU115做计算加速。这款FPGA集成了大量资源,包括各种片上存储器,Xilinx的FPGA中主要有分布式RAM 和 Block RAM 两种存储器。
用分布式RAM 时其实要用到其所在的SliceM,所以要占用其中的逻辑资源;而Block RAM 是单纯的存储资源,但是要一块一块的用,不像分布式RAM 想要多少bit都可以。顶级的Virtex系列FPGA更继承了高达8GB的HBM高宽带内存。时钟方面,有MMCM/PLL。
MMCM:混合模式时钟管理器,用于在与给定输入时钟有设定的相位和频率关系的情况下,生成不同的时钟信号。PLL:锁相环,主要用于频率综合,使用一个PLL可以从一个输入时钟信号生成多个时钟信号。这些主要用在收发器领域。
KU115里还包含5520个DSP,能够大幅度提高图像和视频类任务的处理速度,这是类似GPU的并行运算架构,可以说这片FPGA还包含一个小GPU。这个DSP可以对应乘法累加器、乘加器或单步/n步计数器。
级联多个DSP48E逻辑片可执行复杂的功能。例如,不使用额外的FPGA架构资源的情况下实现复杂乘法器或n阶FIR滤波器。对某些如FFT运算,速度大大提升。Virtex系列顶配有12288个DSP,性能达21897GMAC/s。

Xilinx的Soc+FPGA系列产品则完全可以叫SoC了,其不仅包含多个ARM CPU内核,还有针对安全领域的R5内核,还有Mali 400这样的GPU,最夸张的是RFSoC把射频的ADC/DAC也集成了,还有SD-FEC。
目前集成电路设计基本上都是用IP核搭积木的形式。IP核分为行为(Behavior)、结构(Structure)和物理(Physical)三级不同程度的设计,对应描述功能行为的不同分为三类,即软核(Soft IP Core)、完成结构描述的固核(Firm IP Core)和基于物理描述并经过工艺验证的硬核(Hard IP Core)。软核就是我们熟悉的RTL代码;固核就是指网表;而硬核就是指指经过验证的设计版图。ARM还是以软核为主的。
IP软核(Soft IP Core):通常是用硬件描述语言(hardware Description Language,HDL)文本形式提交给用户,它经过RTL级设计优化和功能验证,但其中不含有任何具体的物理信息。
据此,用户可以综合出正确的门电路级设计网表,并可以进行后续的结构设计,具有很大的灵活性,借助于EDA综合工具可以很容易地与其他外部逻辑电路合成一体,根据各种不同半导体工艺,设计成具有不同性能的器件。
其主要缺点是缺乏对时序、面积和功耗的预见性。而且IP软核以源代码的形式提供的,IP知识产权不易保护。
IP硬核(Hard IP Core)是基于半导体工艺的物理设计,已有固定的拓扑布局和具体工艺,并已经过工艺验证,具有可保证的性能。其提供给用户的形式是电路物理结构掩模版图和全套工艺文件。由于无需提供寄存器转移级文件,因而更易于实现IP保护。其缺点是灵活性和可移植性差。
IP固核(Firm IP Core)的设计程度则是介于软核和硬核之间,除了完成软核所的设计外,还完成了门级电路综合和时序仿真等设计环节。一般以门级电路网表的形式提供给用户。
深鉴只是做了最上层的基于PC的应用算法,要想让算法在嵌入式系统中流畅运行,还需要大量的工作,而这正是Xilinx做的。这就好像图像识别算法,基于PC的几百家都不止,但要一直到车内的ARM系统上,表现会大大折扣,完全不具备实时性,也就无法应用。
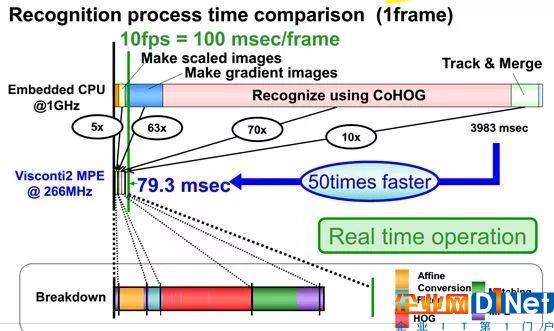
上图是一个典型的行人识别算法HOG+SVM所需要时间的对比,硬核只需要79.3毫秒,软核需要3983毫秒,所以纯软核的设计要么用极简单的算法,要么用英伟达贵到飞起的芯片,即便如此,也不能和硬核比。
所以单纯的算法公司,特别是复杂视觉处理算法公司如果不能将算法用芯片来承载,那就不可能成功。当然,融资还是能成功的,毕竟还有很多投资者不是真正懂技术。








 京公网安备 11010502049343号
京公网安备 11010502049343号